W tym poście nauczymy się, jak można zwiększać cenę produktu o różne stawki. Będziemy to robić dwoma sposobami: za pomocą formuł i wklejania specjalnego.
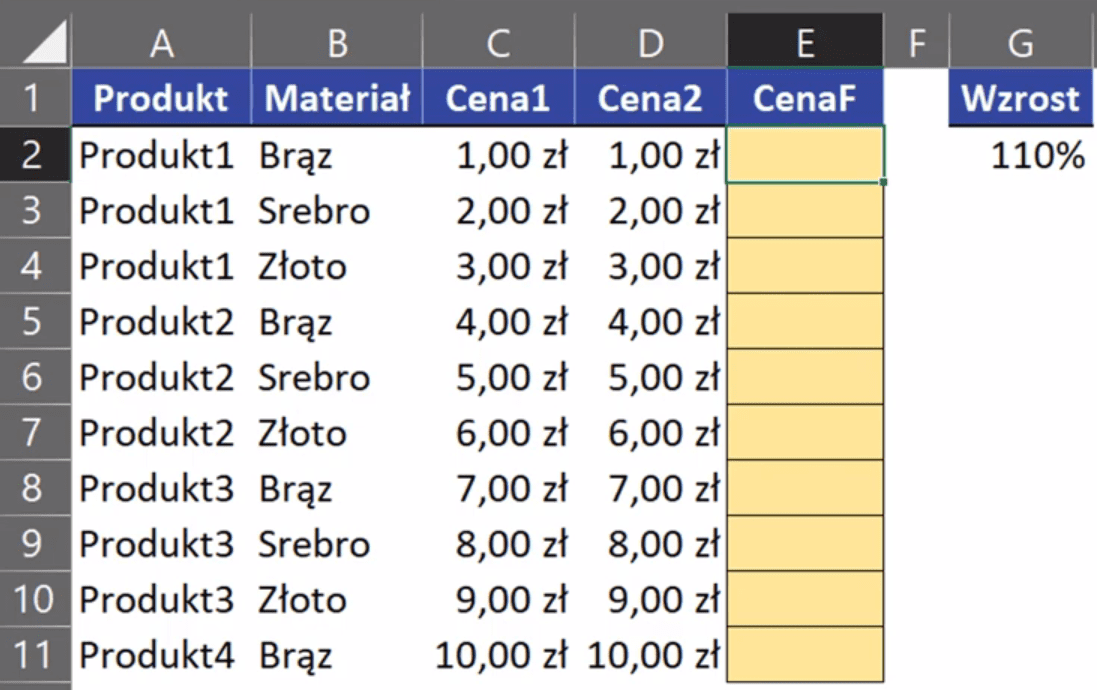
Temat ten omówimy na podstawie przykładowych danych z rys. nr 1.
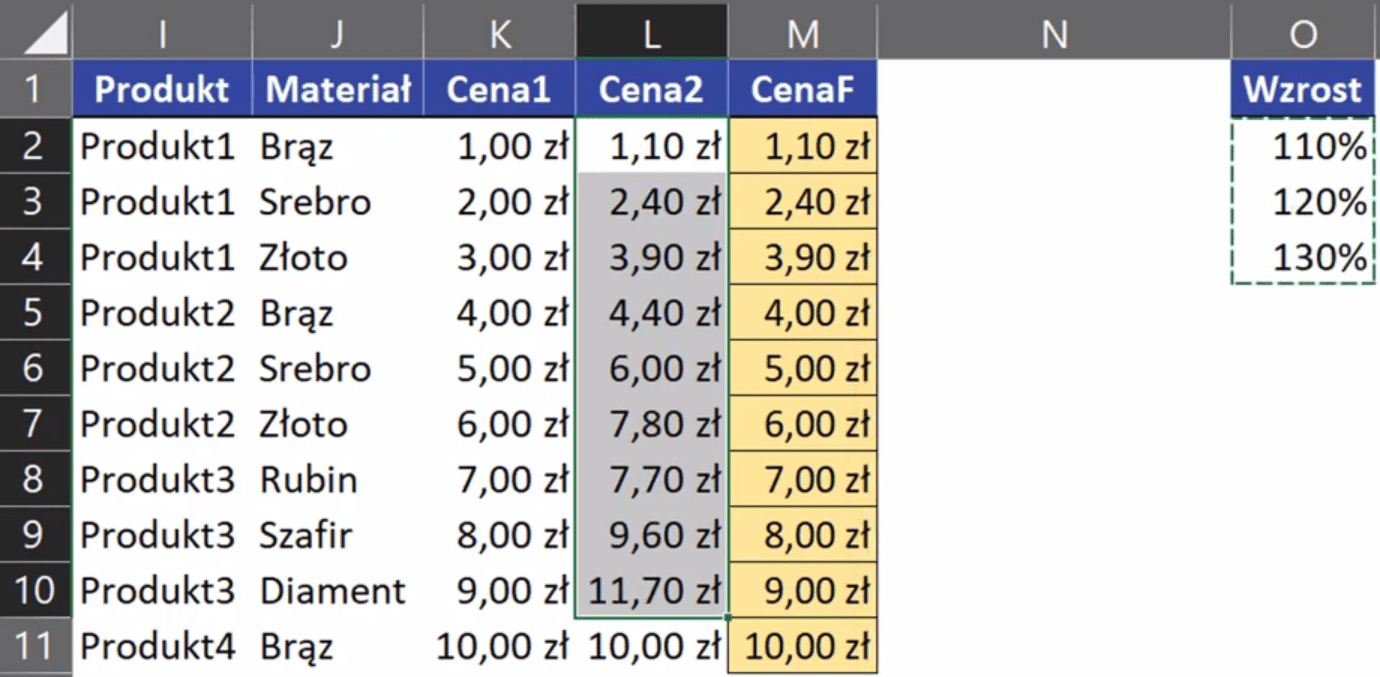
Rys. nr 1 – przykładowe dane (przykład 1)
W pierwszym przykładzie będziemy zwiększać cenę o 10%. Jak widać na rys. nr 1 w kolumnie C mamy aktualną cenę, którą żeby zwiększyć o 10% musimy pomnożyć, czyli mnożymy aktualną cenę razy Wzrost (komórka G2 zablokowana bezwzględnie za pomocą klawisza F4). Zapis formuły powinien wyglądać następująco:
=C2*$G$2
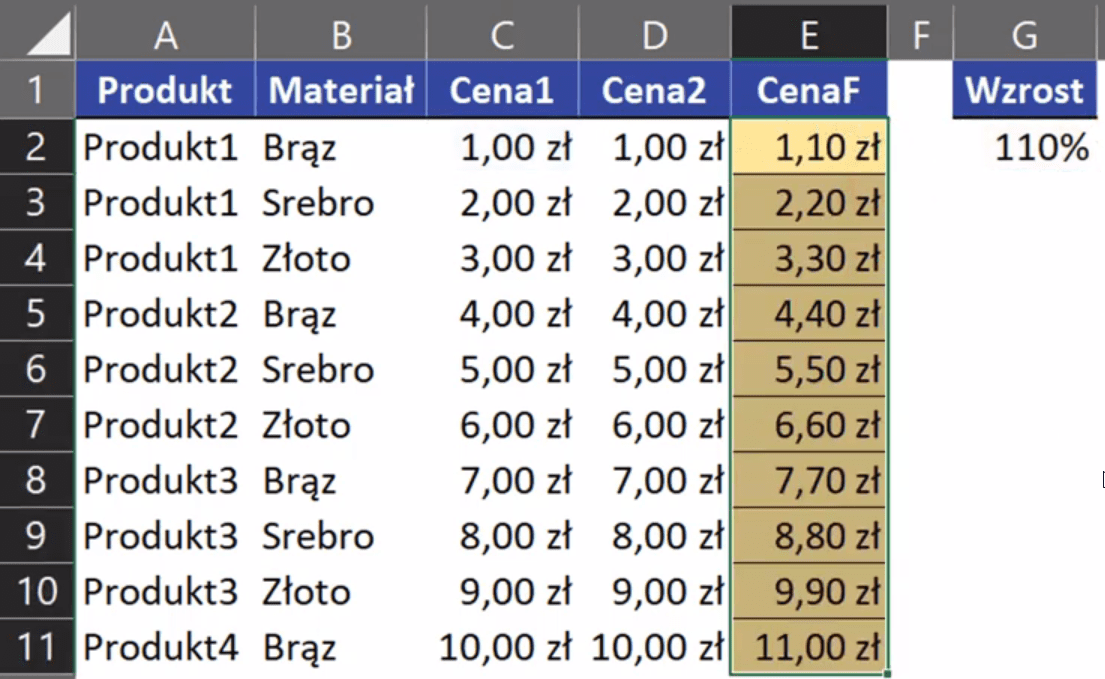
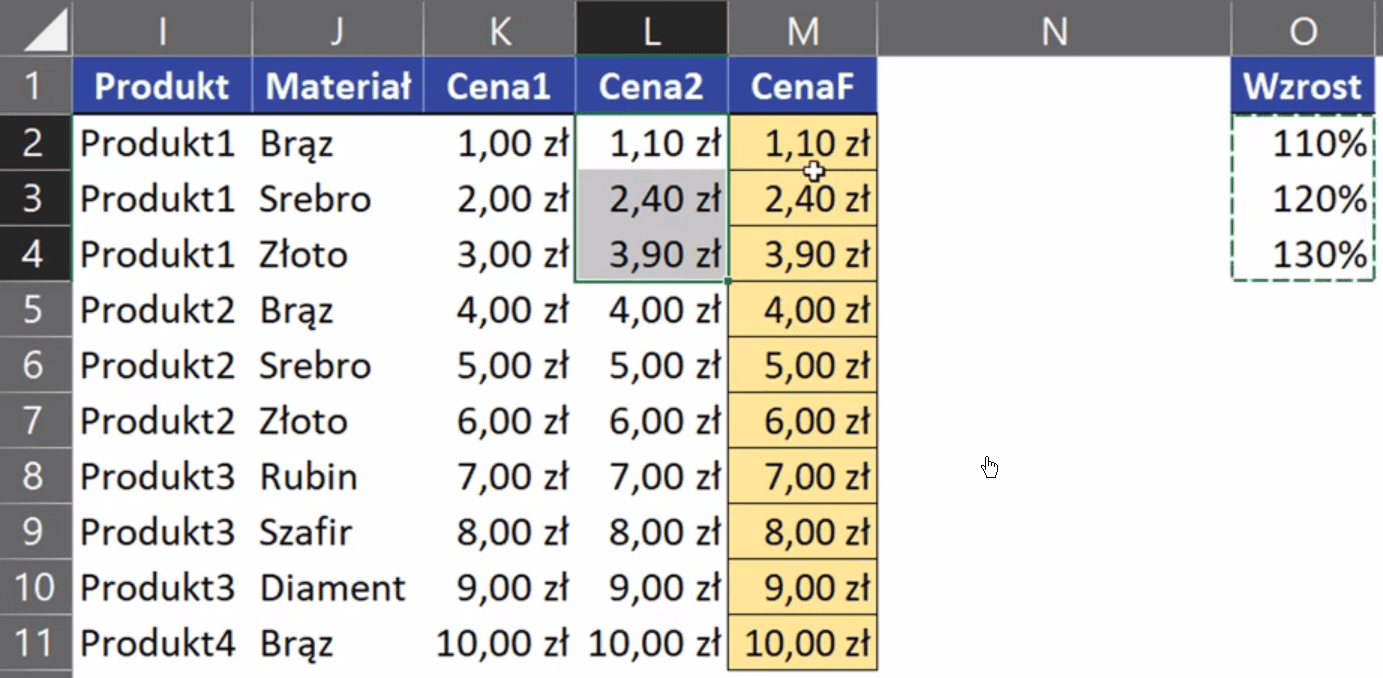
Powyższą formułę zatwierdzamy i kopiujemy w dół. Otrzymamy ceny powiększone o 10% przedstawione na rys. nr 2.
Rys. nr 2 – ceny powiększone o 10% za pomocą formuły
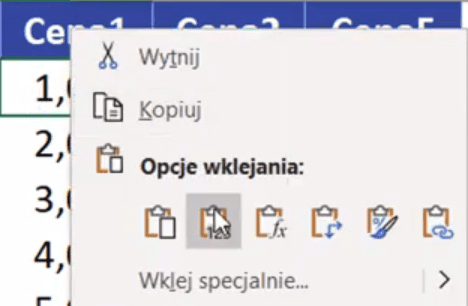
Jak skopiujemy formułę to zaznaczony zakres możemy skopiować za pomocą skrótu klawiszowego Ctrl+C, następnie wklejamy w kolumnie C za pomocą wklejania specjalnego. Klikamy prawym przyciskiem myszy na kolumnę C a następnie z podręcznego menu wybieramy wklej Wartość (W) z Opcji wklejania (rys. nr 3).
Rys. nr 3 – Opcja wklejania Wartość (W)
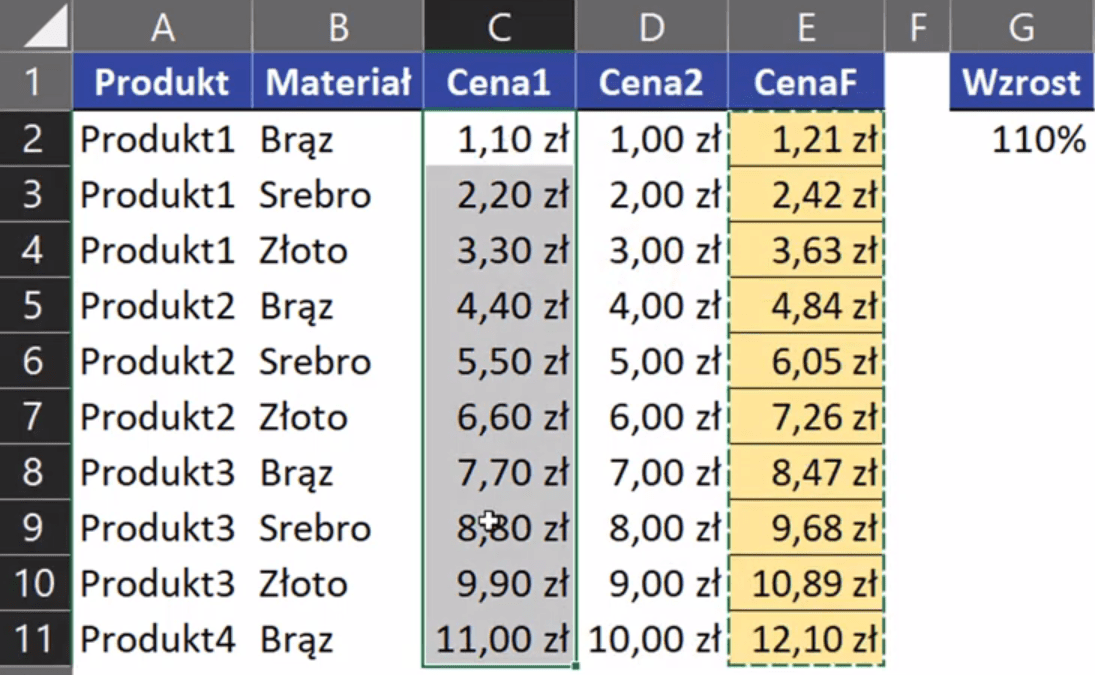
Otrzymamy wklejone nowe ceny do kolumny C (rys. nr 4). Można też zauważyć, że formuła z kolumny E automatycznie się przeliczyła i stworzyła wartości większe o 10% od tych nowych wklejonych cen.
Rys. nr 4 – nowe ceny wklejone do kolumny C
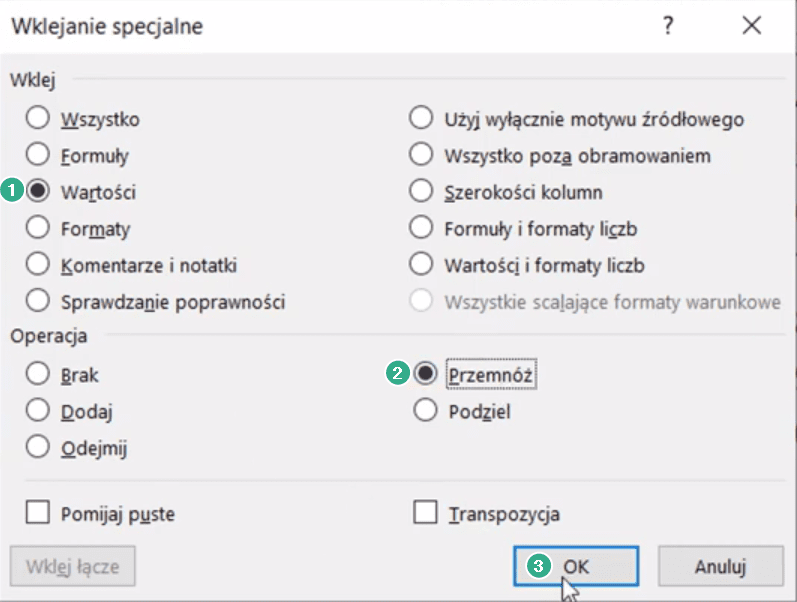
Jest inny sposób, który czasami daje ciekawe możliwości. Zaznaczamy komórkę G2 z wartością informującą o wielkości wzrostu cen i ją kopiujemy za pomocą skrótu klawiszowego Ctrl+C, zaznaczamy zakres D2:D11 i włączamy opcje wklejania specjalnego za pomocą skrótu klawiszowego Alt+Ctrl+V. Otworzy nam się okno wklejania specjalnego, gdzie w polu Wklej zaznaczamy checkbox Wartości (punkt 1 na rys. nr 5), a w polu Operacja zaznaczamy Przemnóż (punkt 2). Tak ustawione parametry wklejania specjalnego zatwierdzamy przyciskiem OK (punkt 3).
Rys. nr 5 – okno Wklejania specjalnego
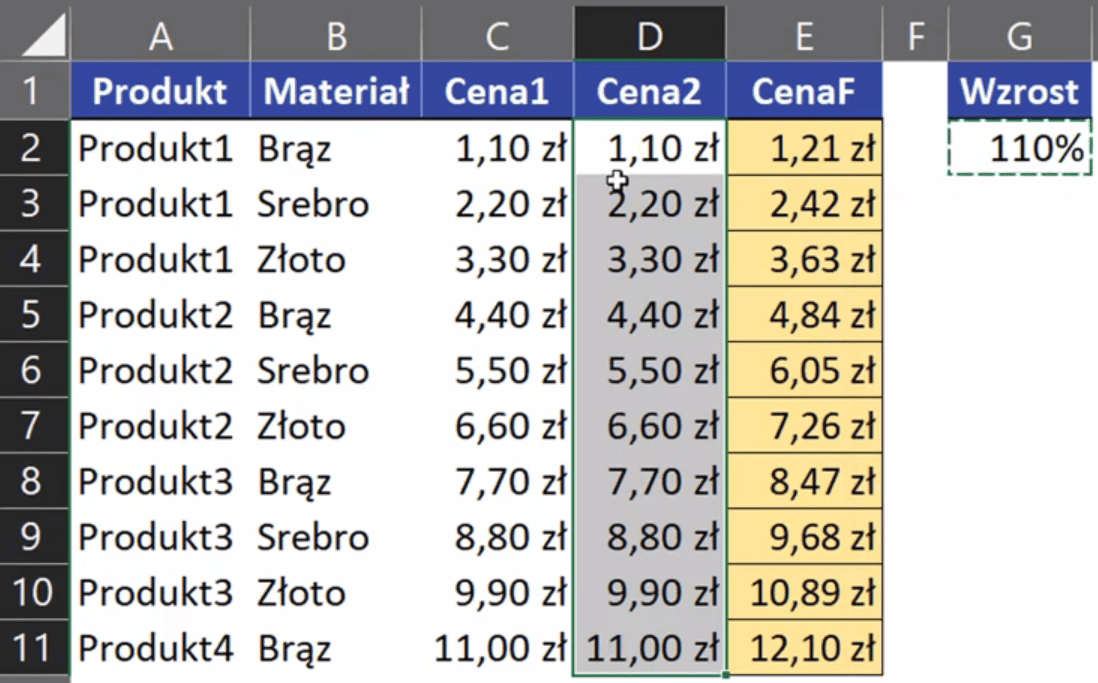
Otrzymamy ceny powiększone o 10% uzyskane za pomocą wklejania specjalnego przedstawione na rys. nr 6.
Rys. nr 6 — ceny powiększone o 10% uzyskane za pomocą wklejania specjalnego
Jeśli mamy takie proste obliczenia, to wklejanie specjalne może być troszeczkę szybsze od formuły.
Przejdziemy teraz do przykładu drugiego, żeby pokazać jak się różni działanie formuły i wklejania specjalnego (rys. nr 7).
Rys. nr 7 — przykładowe dane (przykład 2)
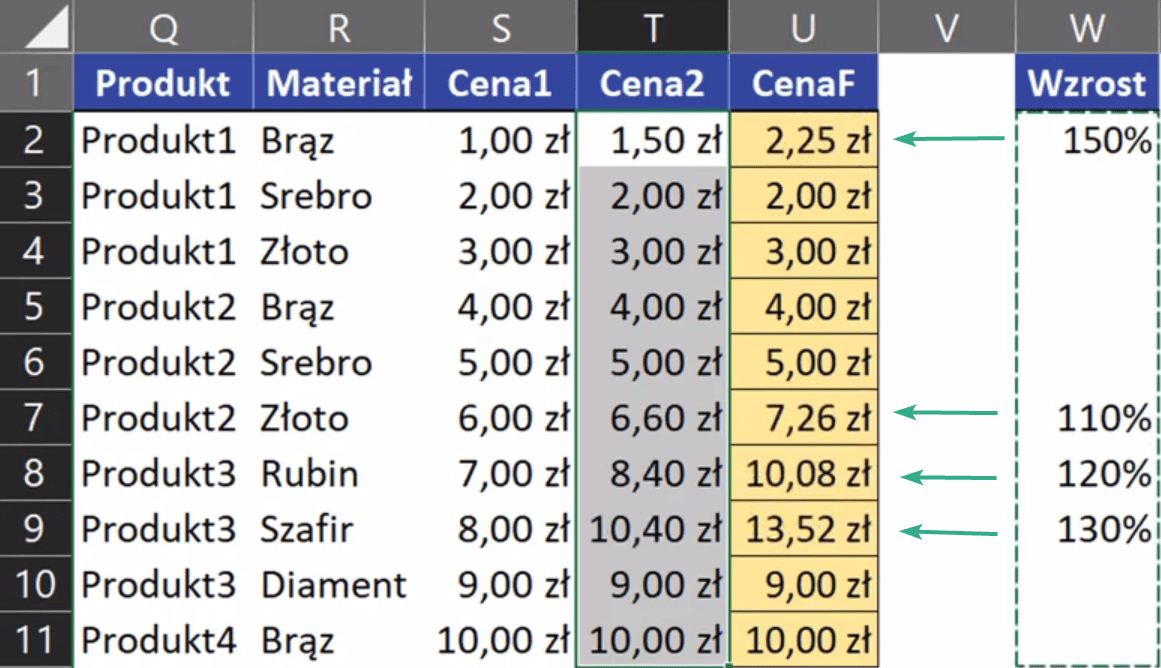
W przykładowych danych mamy podane 3 stawki wzrostu cen. Z założenia mamy 3 wariancje produktów, które różnią się składem. Każdą z nich powinniśmy przemnożyć przez odpowiednią wartość z kolumny Wzrost. Użyjemy do tego funkcji JEŻELI. W argumencie test_logiczny chcemy sprawdzić czy komórka O2 jest pusta (O2=""). Jeżeli warunek jest spełniony to w argumencie wartość_jeżeli_prawda chcemy otrzymać wartość z komórki K2, w przeciwnym razie chcemy aktualną cenę przemnożyć przez Wzrost – argument wartość_jeżeli_fałsz. Zapis formuły powinien wyglądać następująco:
=JEŻELI(O2="";K2;K2*O2)
Powyższą formułę zatwierdzamy i kopiujemy w dół. Otrzymamy nowe ceny uzyskane za pomocą funkcji JEŻELI (rys. nr 8).
Rys. nr 8 — nowe ceny uzyskane za pomocą funkcji JEŻELI
Takie rozwiązanie tworzy nam nową cenę jeśli w kolumnie Wzrost jest podana wartość.
Co ciekawe, jeśli w kolumnie Wzrost mamy 3 komórki wypełnione, a w kolumnie z cenami ilość danych będzie wielokrotnością trzech (lub zaznaczymy tylko np. 9 komórek), to za pomocą wklejania specjalnego uzyskamy interesujący efekt. Zaznaczmy zakres ze wzrostem cen (O2:O4) i skopiujmy go za pomocą skrótu klawiszowego Ctrl+C, następnie zaznaczmy tylko 9 komórek w kolumnie L i za pomocą skrótu klawiszowego Alt+Ctrl+V otwórzmy okno Wklejania specjalnego. W tym oknie w polu Wklej zaznaczamy checkbox Wartości, a w polu Operacja wybieramy Przemnóż (jak na rys. nr 5). Tak ustawione parametry zatwierdzamy przyciskiem OK.
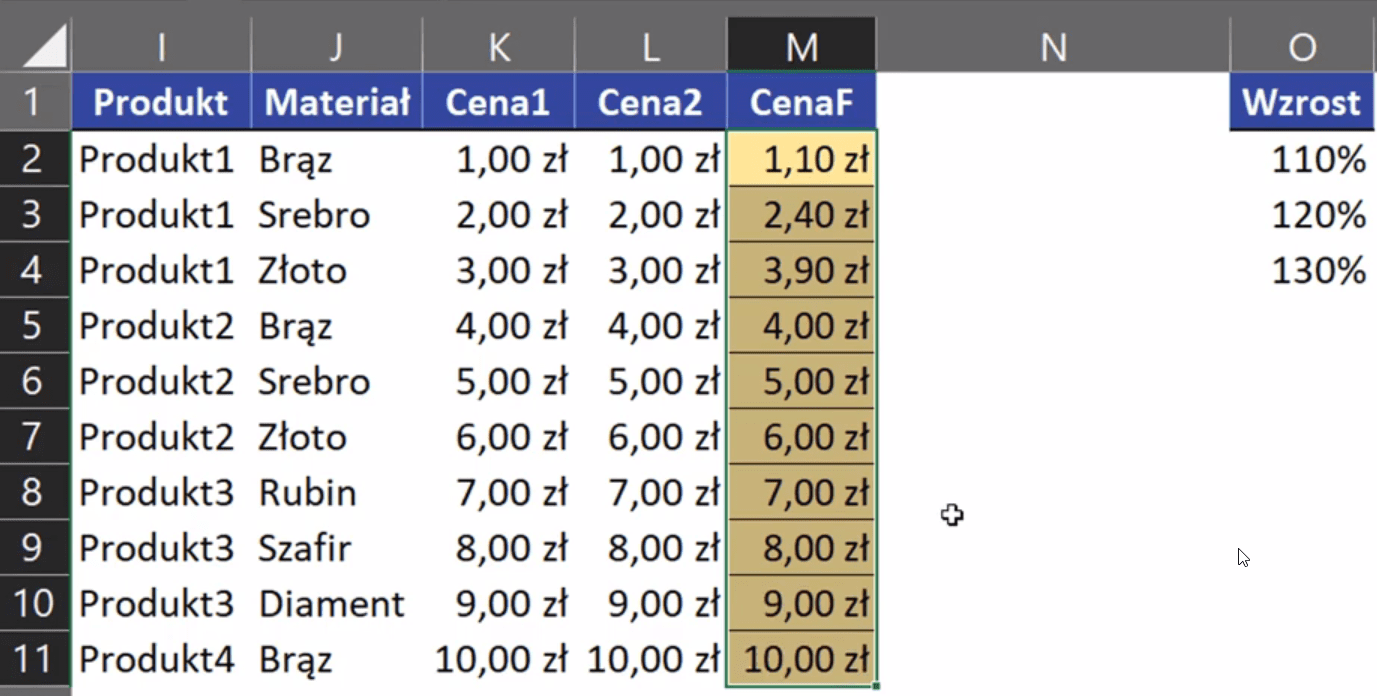
Otrzymamy nowe ceny w kolumnie L przedstawione na rys. nr 9.
Rys. nr 9 – nowe ceny uzyskane za pomocą wklejania specjalnego
Jak widać na rysunku powyżej każda grupa 3 cen została przemnożona przez wartości z kolumny O. Mianowicie po kolei pierwszy element z grupy Produkt1 został pomnożony przez wartość 110%, drugi element z grupy Produkt1 został pomnożony przez wartość 120% i analogicznie 3 produkt przez 130% i tak dalej, aż do 9tego produktu.
A co w sytuacji, jeśli zaznaczony zakres w kolumnie L nie będzie wielokrotnością ilości komórek w kolumnie Wzrost? Sprawdzimy to w ten sposób, że zaznaczamy zakres O2:O4, następnie zaznaczamy zakres L2:L11 i uruchamiamy Wklejanie specjalne. Analogicznie jak wcześniej zaznaczamy Wartość i Przemnóż (jak na rys. nr 5). Zatwierdzamy przyciskiem OK. Otrzymamy wyniki przedstawione na rys. nr 10.
Rys. nr 10 – wyniki wklejania specjalnego
Jak widać na rysunku powyżej zostały pomnożone tylko 3 pierwsze komórki. Reszta cen nie uległa zmianie.
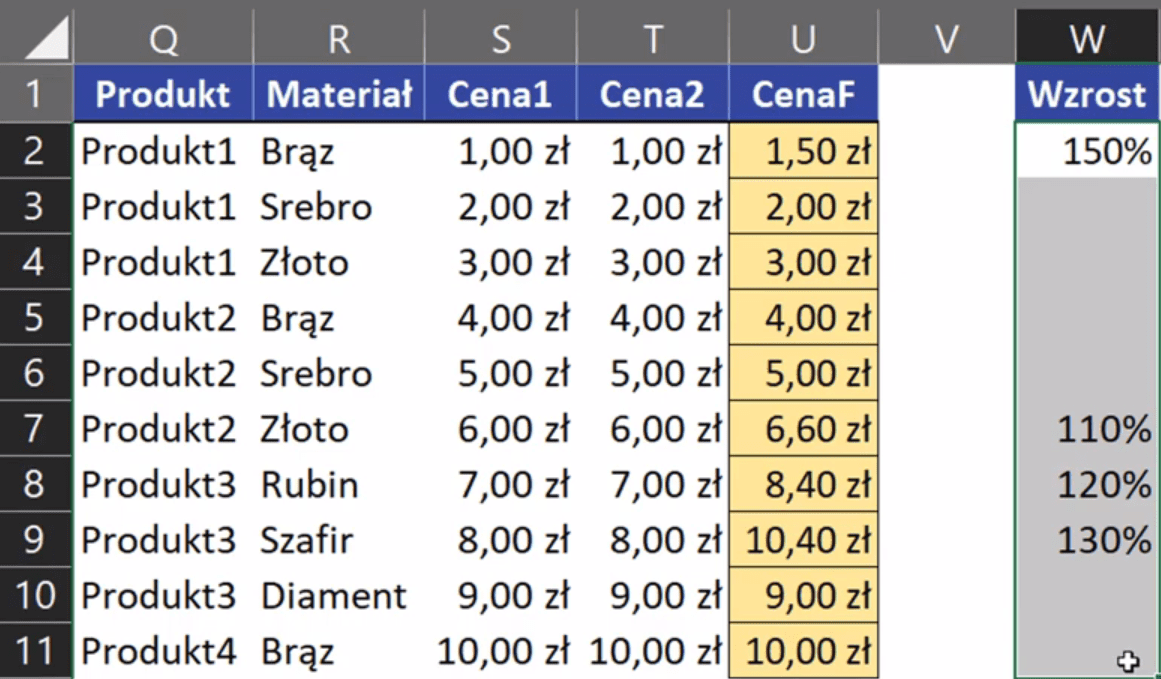
Przejdziemy teraz do trzeciego przykładu. Przykładowe dane zostały przedstawione na rys. nr 11.
Rys. nr 11 – przykładowe dane (przykład 3)
W rozwiązaniu za pomocą funkcji JEŻELI formuła wygląda analogicznie jak w poprzednim przykładzie. Zapis funkcji w kolumnie U powinien wyglądać następująco:
=JEŻELI(W2="";T2;T2*W2)
Czyli jeśli komórka ze wzrostem ceny nie jest pusta, chcemy zwiększyć cenę o 15%. Jeśli jest pusta ma pozostać aktualna cena.
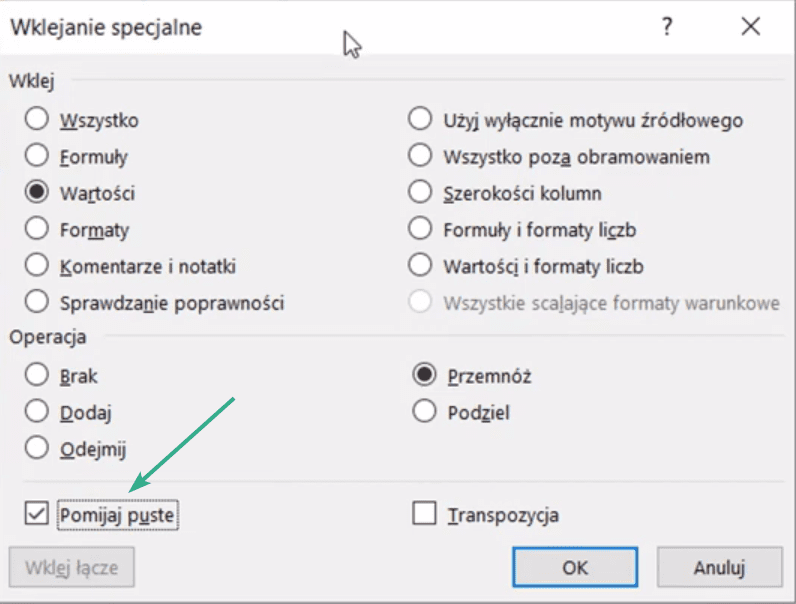
Teraz zrobimy takie samo rozwiązanie za pomocą wklejania specjalnego. Zaznaczamy zakres W2:W11i kopiujemy, następnie zaznaczamy zakres w kolumnie T (T2:T11) i uruchamiamy Wklejanie specjalne za pomocą skrótu klawiszowego Ctrl+Alt+V. Ponownie zaznaczamy Wartość i Przemnóż. Istotne jest, aby tutaj zaznaczyć dodatkowy checkbox Pomijaj puste. Zatwierdzamy przyciskiem OK (rys. nr 12).
Ten dodatkowy checkbox sprawia, że jeśli w danym wierszu mamy pustą komórkę w kolumnie Wzrost, to ta cena nie jest mnożona. Nie jest wykonywana żadna operacja w tym wierszu. Otrzymamy dane przedstawione na rys. nr 13.
Rys. nr 13 – wyniki uzyskane za pomocą wklejania specjalnego z pominięciem pustych komórek
Jak widać na rys. powyżej zostały wykonane operacje zmiany ceny tylko w wierszach, gdzie w kolumnie Wzrost mieliśmy niepuste komórki.
Podsumowując opcja Wklejania specjalnego pozwala nam przemnożyć ceny przez różne stawki wzrostu. Często może być to szybszym i ciekawszym rozwiązaniem niż pisanie formuł.
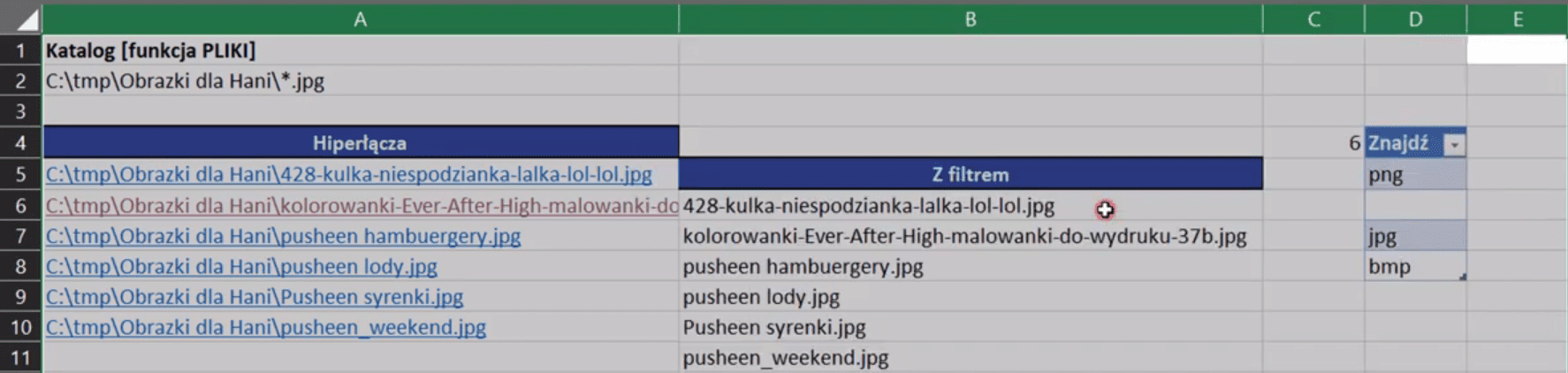
W tym poście pokażemy, jak stworzyć listę hiperłączy do plików znajdujących się w konkretnym folderze przy użyciu makr.
Temat ten omówimy na podstawie przykładowych danych z rys. nr 1. Ważne jest, że jeżeli chcemy korzystać z tej funkcji, musimy stworzyć plik z rozszerzeniem .xlsm, czyli taki, który obsługuje makra.
Rys. nr 1 – przykładowe dane
Przede wszystkim musimy znać polską wersję funkcji, której chcemy użyć (funkcja PLIKI). Jeśli tej funkcji podamy ścieżkę dostępu i zakończymy to znakiem gwiazdki (*) lub odpowiednim rozszerzeniem, to będzie ona pobierać pliki z tego katalogu. Odpowiednie połączenie formuł zapewni nam zbudowanie hiperłączy.
Mamy kilka obostrzeń, jeśli chodzi o korzystanie z tych funkcji. Funkcja nazywa się PLIKI, ale jeśli w komórce zaczniemy pisać słowo "pliki" to takiej funkcji nie znajdziemy, co widać na rys. nr 2.
Rys. nr 2 – problem ze znalezieniem funkcji PLIKI
Tą funkcję możemy zbudować tylko w Menedżerze nazw. W tym celu wybieramy polecenie Menedżer nazw z karty Formuły (rys. nr 3). Możemy również użyć skrótu klawiszowego Ctrl+F3.
Rys. nr 3 – polecenie Menedżer nazw
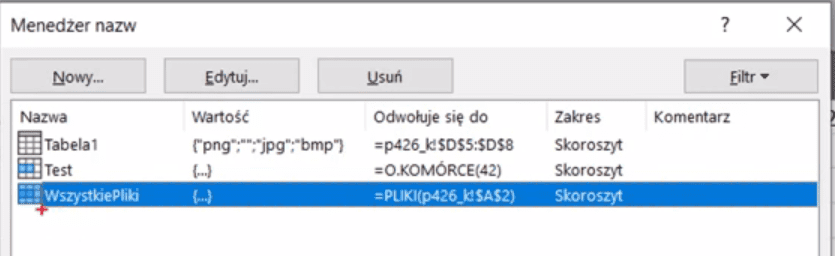
Otworzy nam się okno Menedżera nazw, gdzie możemy sobie zbudować funkcję PLIKI, która odwołuje się do komórki A2, czyli do ścieżki dostępu. Na tej podstawie funkcja zwraca listę plików z tego katalogu (rys. nr 4).
Rys. nr 4 – okno Menedżera nazw
Jak widać na rysunku powyżej nazwaliśmy tą funkcję WszystkiePliki. Korzystając z tego, że używamy Excela tablicowego, po wpisaniu funkcji WszystkiePliki i jej zatwierdzeniu, funkcja zwróci nam listę wszystkich plików (rys. nr 5).
Rys. nr 5 – zwrócona lista wszystkich plików
Jak widać na rysunku powyżej domyślnie lista ta jest zwracana w poziomie, w jednym wierszu, a nie w kolumnie. W Excelu tablicowym wystarczyłoby dołożyć funkcję TRANSPONUJ, żeby wyniki otrzymać w pionie, czyli w jednej kolumnie.
Zakładamy jednak, że jesteśmy we wcześniejszej wersji Excela i chcemy wyciągnąć takie informacje jak widać na rys. nr 1. W komórce A5 wpisujemy nazwę funkcji WszystkiePliki. Wiemy, że ona rozsuwa wyniki w poziomie, a my chcemy otrzymać je w pionie. W Klasycznym Excelu nie mamy możliwości transponowania wyników ani rozlewania formuły. Dlatego musimy użyć funkcji INDEKS. Pierwszym argumentem funkcji jest tablica, czyli wyniki z funkcji WszystkiePliki. Kolejny argument to nr_wiersza, czyli wpisujemy wartość 1. Zapis formuły powinien wyglądać następująco:
=INDEKS(WszystkiePliki;1)
Po zatwierdzeniu formuły otrzymamy nazwę jednego pliku przedstawioną na rys. nr 6.
Rys. nr 6 – zwrócona nazwa jednego pliku
Podając w funkcji kolejne numery wiersza możemy otrzymać zwrócone kolejne elementy/pliki. Możemy takie podawanie poszczególnych numerów wierszy zastąpić funkcją ILE.WIERSZY. Pierwszym argumentem funkcji jest tablica, czyli zakres od komórki $A$5 zablokowanej bezwzględnie do komórki A5 niezablokowanej. Jak będziemy formułę kopiować w dół, to komórka A5 nie zablokowana bezwzględnie będzie się przesuwać i tym samym zwracać kolejne numery wierszy. Zapis formuły powinien wyglądać następująco:
=INDEKS(WszystkiePliki;ILE.WIERSZY($A$5:A5))
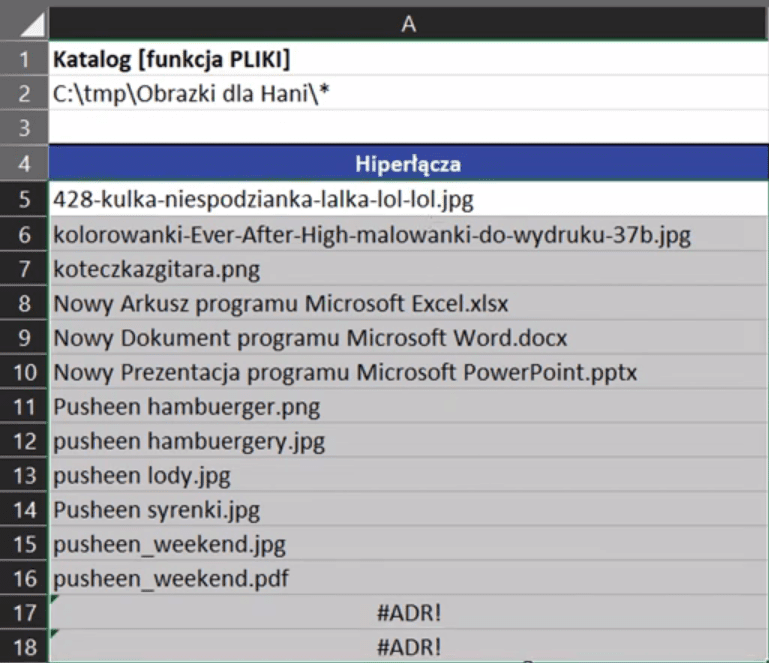
Powyższą formułę zatwierdzamy i kopiujemy w dół. Otrzymamy dane przedstawione na rys. nr 7.
Rys. nr 7 – lista elementów z pliku
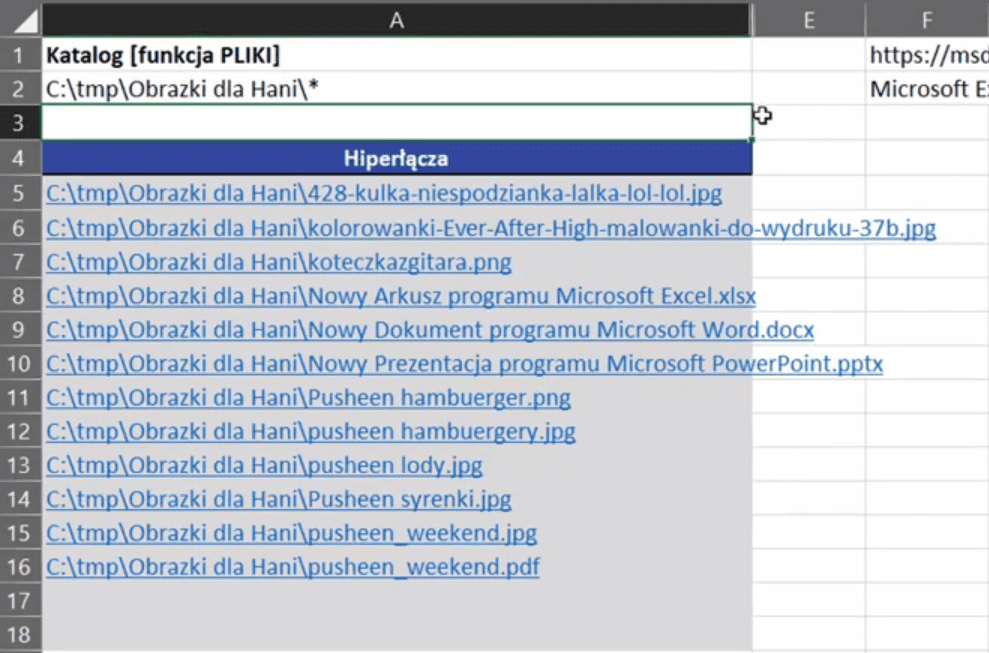
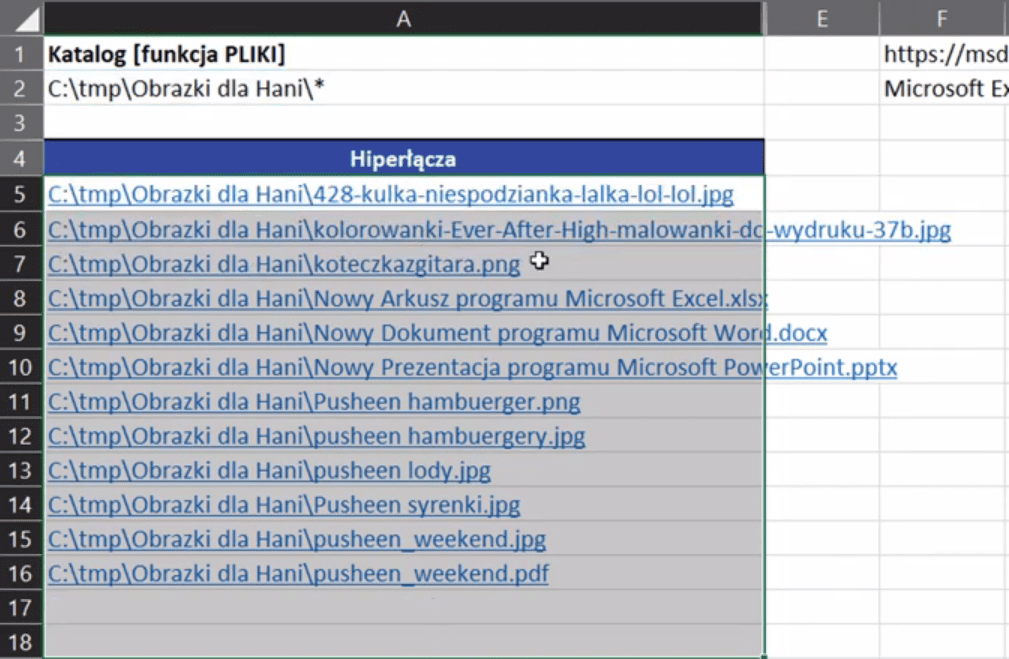
Jeśli w ilości skopiowanych komórek w dół przekroczymy ilość elementów w folderze, to Excel zwróci nam błąd adresu #ADR!. Mamy wyciągnięte wszystkie pliki, które znajdują się w tym katalogu. Aby zbudować hiperłącze, potrzebujemy ścieżki dostępu do tych plików (C:\tmp\Obrazki dla Hani\*). Wtedy możemy połączyć nasze dane wklejając skopiowany adres po znaku =. Jako, że jest to tekst, musimy go wstawić w podwójnych cudzysłowach. Następnie połączyć wstawiony adres z resztą formuły za pomocą znaku ampersand (&). Zapis formuły powinien wyglądać następująco:
="C:\tmp\Obrazki dla Hani\"&INDEKS(WszystkiePliki;ILE.WIERSZY($A$5:A5))
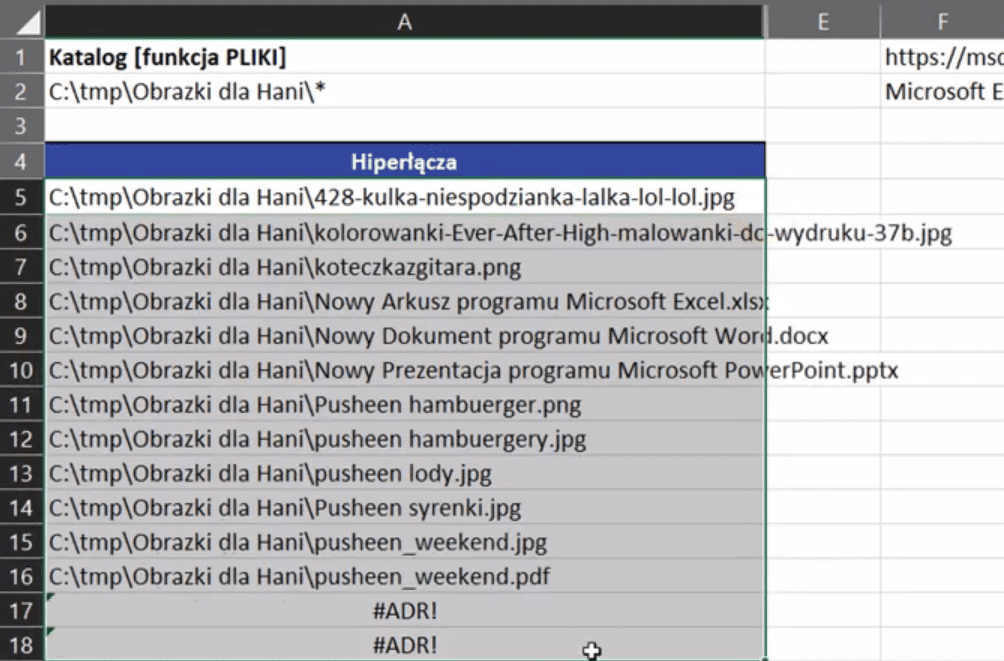
Po zatwierdzeniu powyższej formuły i skopiowaniu jej na komórki poniżej otrzymamy kompletne ścieżki dostępu do każdego z plików (rys. nr 8).
Rys. nr 8 – pełne ścieżki dostępu do każdego z plików w katalogu
Po otrzymaniu kompletnych ścieżek dostępu pozostaje nam dołożenie funkcji HIPERŁĄCZE, której argumentem jest łącze_lokalizacja, czyli wynik naszej poprzedniej formuły. Jeśli chcemy, możemy dodać opcjonalny argument, czyli przyjazna_nazwa. Zapis formuły powinien wyglądać następująco:
=HIPERŁĄCZE("C:\tmp\Obrazki dla Hani\"&INDEKS(WszystkiePliki;ILE.WIERSZY($A$5:A5)))
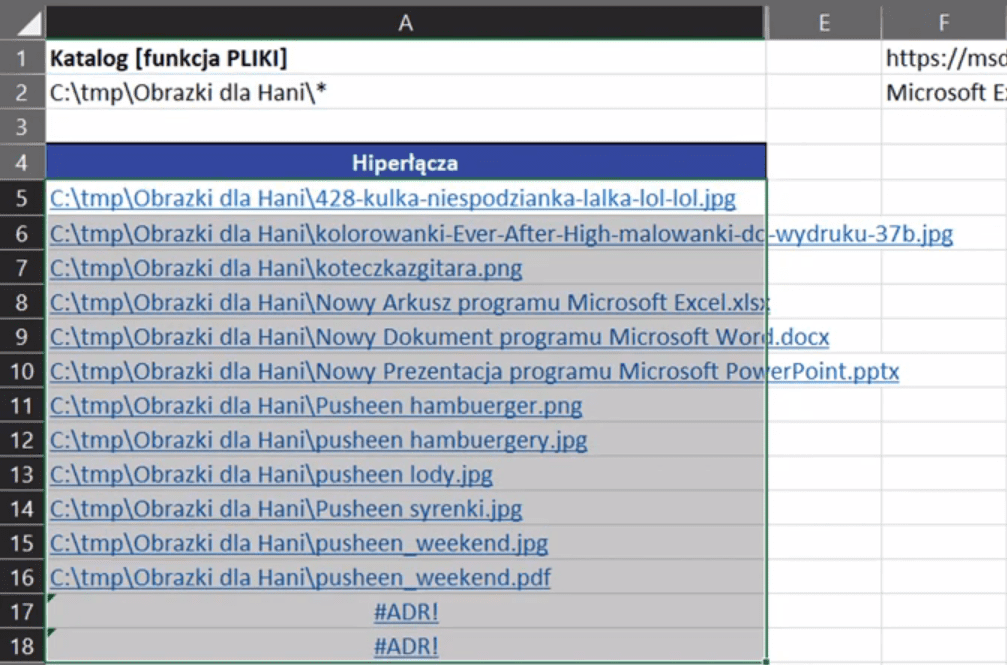
Po zatwierdzeniu formuły i skopiowaniu jej w dół otrzymamy hiperłącza do poszczególnych elementów katalogu przedstawione na rys. nr 9.
Rys. nr 9 – hiperłącza do poszczególnych elementów katalogu
Hiperłącza zostały również dodane dla ostatnich dwóch wierszy zawierających błędy. Aby tego uniknąć, możemy dołożyć funkcję JEŻELI.BŁĄD. Pierwszym argumentem funkcji jest wartość, czyli wynik funkcji HIPERŁĄCZE. Drugi argument funkcji to wartość_jeśli_błąd, czyli co chcemy, aby zwróciła funkcja jeśli napotka błąd – u nas pusty ciąg tekstowy (""). Zapis formuły powinien wyglądać następująco:
=JEŻELI.BŁĄD(HIPERŁĄCZE("C:\tmp\Obrazki dla Hani\"&INDEKS(WszystkiePliki;ILE.WIERSZY($A$5:A5)));"")
Po zatwierdzeniu formuły otrzymamy prawidłowe hiperłącza przedstawione na rys. nr 10.
Rys. nr 10 – prawidłowe hiperłącza
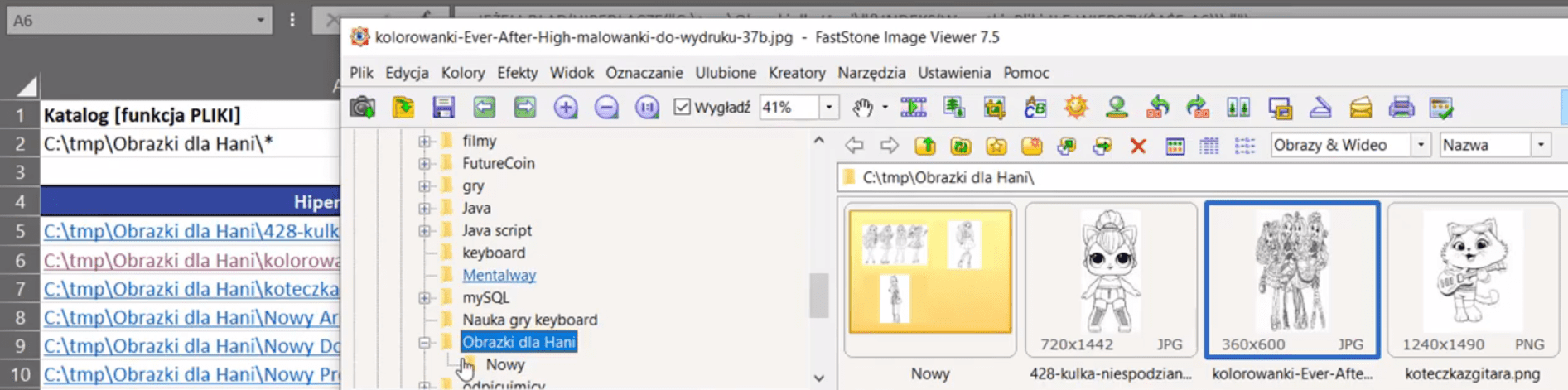
Jeśli klikniemy w dowolne hiperłącze, Excel otworzy nam odpowiedni katalog i wyświetli wybrany obrazek (rys. nr 11).
Rys. nr 11 – wyświetlony obrazek po kliknięciu hiperłącza
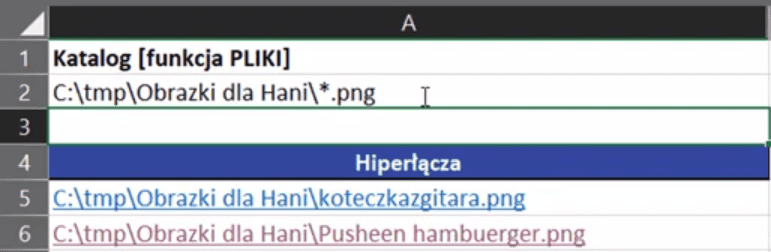
Funkcja PLIKI umożliwia filtrowanie danych. Jeśli do adresu katalogu w komórce A2 dopiszemy rozszerzenie .png, to Excel przefiltruje dane i wyświetli tylko hiperłącza zawierające pliki z tym rozszerzeniem (rys. nr 12).
Rys. nr 12 – przefiltrowane dane – pliki z rozszerzeniem .png
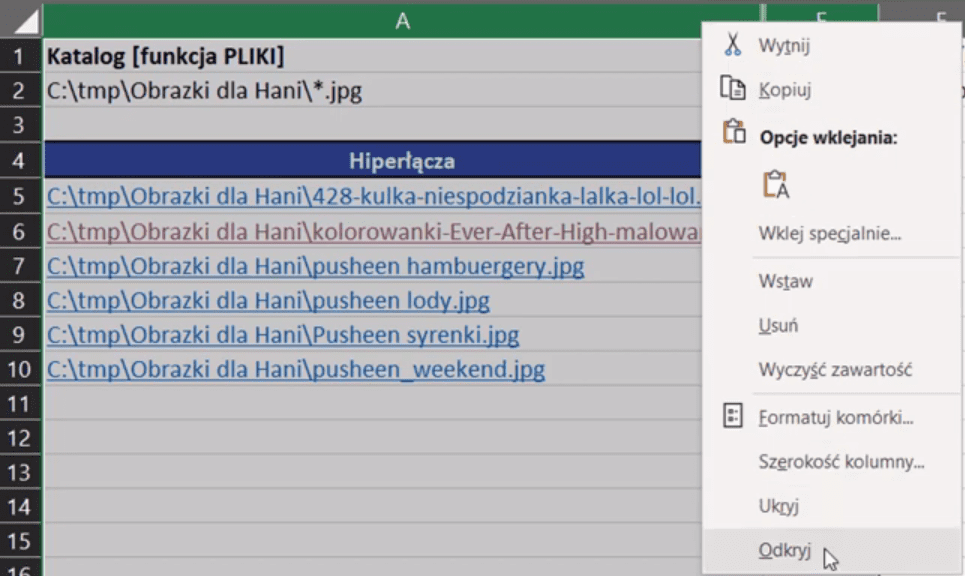
W ten sposób możemy łatwo filtrować po jednym rodzaju rozszerzenia. Niestety, żeby filtrować po większej ilości rozszerzeń, musimy zaznaczyć wybrany zakres i kliknąć prawym przyciskiem myszki na nagłówki kolumn i z podręcznego menu wybrać opcję Odkryj (rys. nr 13).
Rys. nr 13 – opcja Odkryj w podręcznym menu
Wyświetlą nam się "dodatkowe" dane przedstawione na rys. nr 14.
Rys. nr 14 – odkryte dane
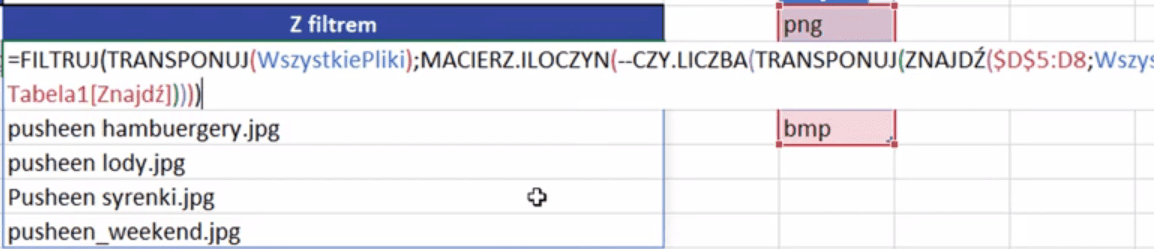
Po tymi danymi są dużo bardziej skomplikowane formuły, które są potrzebne do zbudowania listy plików spełniających wybrane warunki (rys. nr 15). Tutaj niezbędne okazują się funkcje z Excela tablicowego, bo Excel klasyczny potrzebowałby dużo bardziej skomplikowanych formuł.
Rys. nr 15 – skomplikowane formuły z użyciem Excela tablicowego
Jeśli zależy nam na liście wszystkich plików z katalogu lub na jednym konkretnym rodzaju plików, to funkcja PLIKI jest tutaj najlepszym rozwiązaniem.
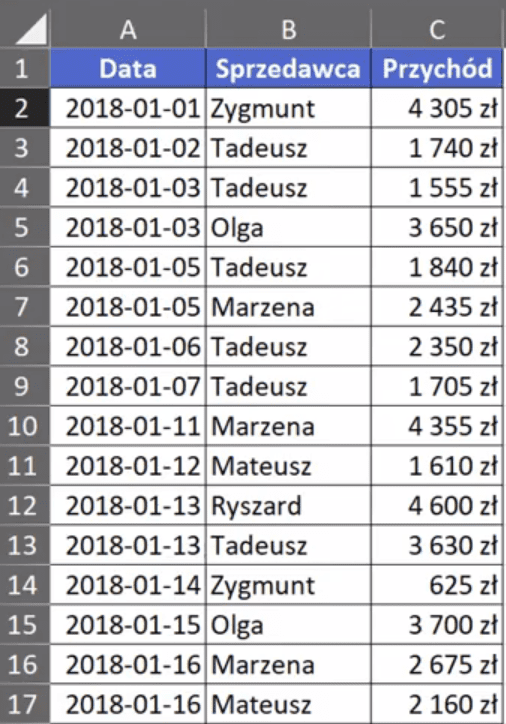
W tym poście nauczymy się, jak uzyskać pełne nazwy miesięcy w tabeli przestawnej.
Zadanie to wykonamy na podstawie przykładowych danych z rys. nr 1.
Rys. nr 1 – przykładowe dane
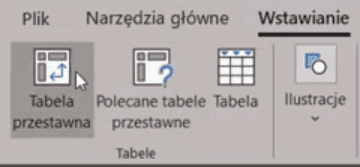
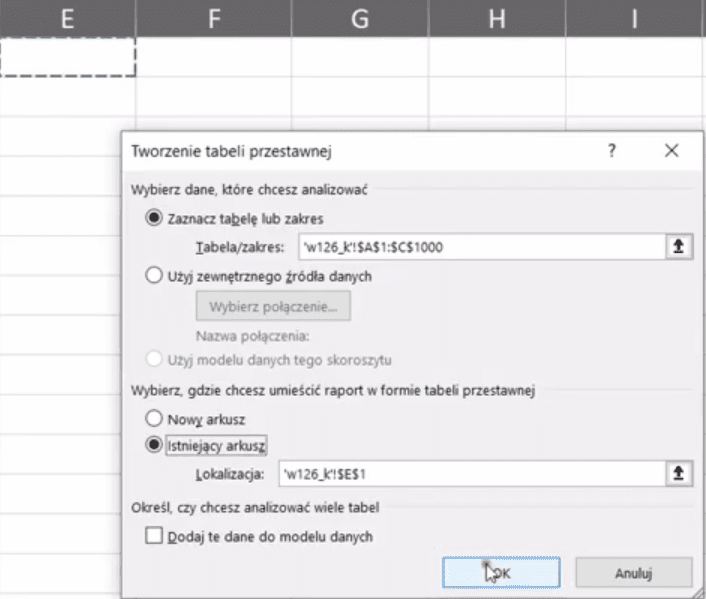
Najpierw na podstawie naszych danych musimy stworzyć tabelę przestawną. W tym celu zaznaczamy pojedynczą komórkę w danych, następnie wybieramy polecenie Tabela przestawna z karty Wstawianie (rys. nr 2).
Rys. nr 2 – polecenie Tabela przestawna
Otworzy nam się okno Tworzenia tabeli przestawnej, gdzie musimy wybrać miejsce jej wstawienia – wybieramy checkbox Istniejący arkusz i zaznaczamy komórkę, gdzie tabela ma zostać wstawiona. Tak określone parametry tabeli przestawnej zatwierdzamy przyciskiem OK (rys. nr 3).
Rys. nr 3 – okno Tworzenia tabeli przestawnej
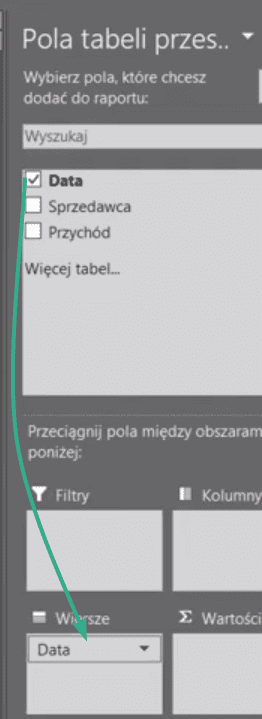
Otrzymamy pole tabeli przestawnej wstawione w wybranej przez nas lokalizacji. Otworzy nam się panel boczny Pól tabeli przestawnej, gdzie przeciągamy pole Data do obszaru etykiet Wierszy (zaznaczone strzałką na rys. nr 4).
Rys. nr 4 – przeciągnięte dane do Etykiet Wierszy
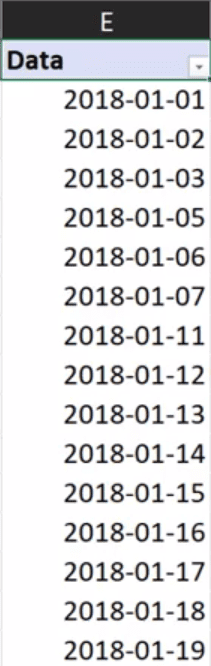
Otrzymamy tabelę przestawną z datami przedstawioną na rys. nr 5.
Rys. nr 5 – tabela przestawna z datami
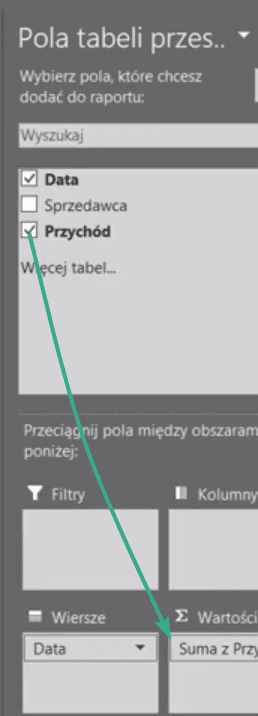
Teraz będziemy chcieli pogrupować sobie te dane po miesiącach, żeby później kiedy przeciągniemy Przychód do pola Podsumowań, móc otrzymać dane pogrupowane i podsumowane według poszczególnych miesięcy (rys. nr 6).
Rys. nr 6 – przeciągnięte dane do pola Suma Wartości
Żeby pogrupować daty musimy kliknąć prawym przyciskiem myszy na dowolną z nich, następnie z podręcznego menu wybrać opcję Grupuj (rys. nr 7).
Rys. nr 7 – opcja Grupuj w podręcznym menu
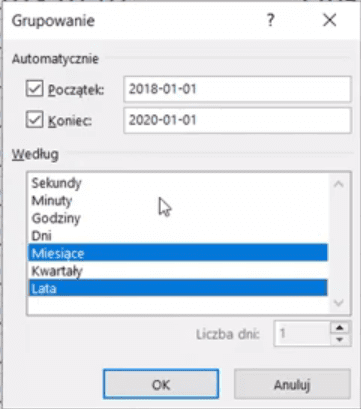
Otworzy nam się okno Grupowania, gdzie w polu Według wybieramy po czym chcemy pogrupować dane – w naszym przykładzie zaznaczamy Miesiące i Lata. Tak ustawione parametry grupowania zatwierdzamy przyciskiem OK (rys. nr 8).
Rys. nr 8 – okno Grupowania
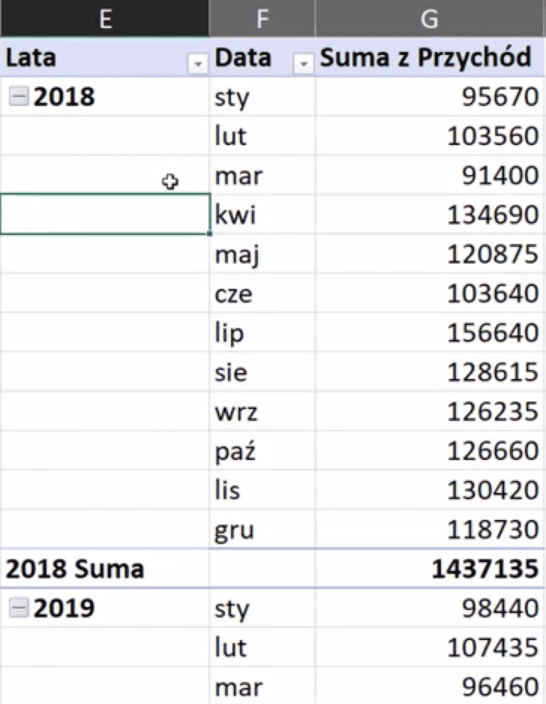
Otrzymamy pogrupowane dane przedstawione na rys. nr 9.
Rys. nr 9 – pogrupowane dane
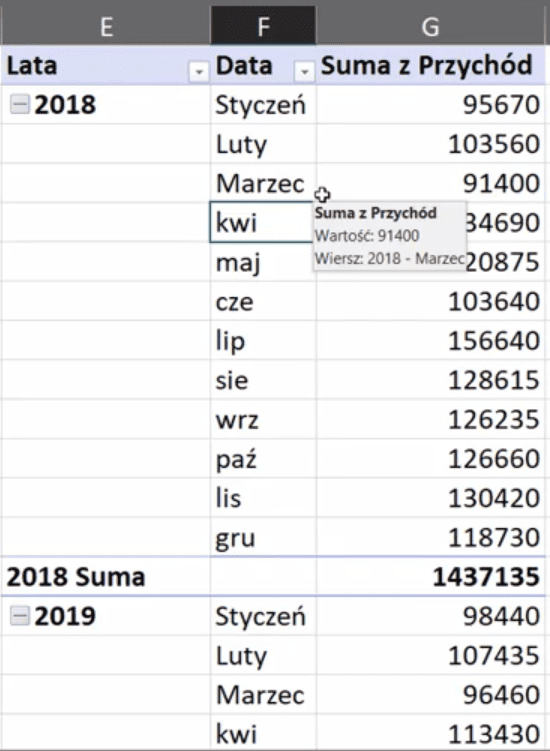
Mamy pogrupowane dane według lat i miesięcy. Problem polega na tym, że chcemy aby pokazywały się całe nazwy miesięcy a nie tylko ich skróty. Nigdzie w opcjach tabeli przestawnej nie udało mi się znaleźć takiej opcji. Da się natomiast przy grupowaniach zrobić pewną sztuczkę. Mianowicie tam, gdzie mamy zgrupowane dane da się wpisać inną wartość. Zaznaczamy komórkę z nazwą sty i ręcznie wpisujemy Styczeń. Ważne jest to, że jeśli raz zmienimy nazwę miesiąca to ona zmieni się też dla kolejnych lat zgrupowanych danych. Trochę niestety pracy trzeba wykonać, bo musimy ręcznie zmienić nazwy wszystkich miesięcy w roku, ale otrzymamy zmieniona nazwy dla wszystkich danych, nawet w kolejnych latach (rys. nr 10).
Rys. nr 10 – zmienione nazwy miesięcy w kolejnych latach po ręcznej zmianie nazwy
Zdarza się, że wstążka w Excelu ma małe ikonki jak widać na rys. nr 1.
Rys. nr 1 – małe ikonki na wstążce Excela
Jak to bywa coś niechcący wciśniemy, czy usiądziemy do pracy na komputerze służbowym, który ma inne ustawienia niż my preferujemy. Nauczymy się teraz jak wrócić do standardowego wyglądu wstążki przedstawionego na rys. nr 2.
Rys. nr 2 – standardowy wygląd wstążki Excela
Efekt zmniejszenia ikonek wynika z pewnej opcji, związanej tak naprawdę z dotykowym ekranem. W takiej sytuacji zależy nam, żeby powierzchnia dotykowa (wyboru opcji), odległość pomiędzy poszczególnymi opcjami była większa. Żeby zmienić ten wygląd wystarczy rozwinąć ikonkę ze strzałką na pasku narzędzi Szybki dostęp, następnie wybrać polecenie Tryb dotyku/myszy (rys. nr 3).
Rys. nr 3 – Tryb dotyku/myszy
W ten sposób włączyliśmy sobie dodatkową opcję na pasku narzędzi Szybki dostęp (rys. nr 4). Zgodnie z informacjami, jakie udało mi się znaleźć w sieci, ten problem może występować od Excela 2016.
Rys. nr 4 – dodatkowa opcja na pasku narzędzi Szybki dostęp
Jak widać na rysunku powyżej możemy w łatwy i szybki sposób zmieniać wygląd wstążki Excela. Musimy tylko zdecydować, czy zależy nam na szerszych odstępach między ikonkami wstążki, żeby łatwiej operować programem w sposób dotykowy, czy też będziemy używać myszki i wystarczą nam standardowe odległości.
Kiedy już zdecydujemy, jakiej opcji wolimy używać, ikonka wyboru trybu dotyku/myszy nie jest nam potrzebna. Dlatego klikamy na nią prawym przyciskiem myszy i z podręcznego menu wybieramy polecenie Usuń z paska narzędzi Szybki dostęp (rys. nr 5).
Rys. nr 5 – polecenie Usuń z paska narzędzi Szybki dostęp
W tym poście nauczymy się, jak wyciągnąć długość przedmiotu w centymetrach z nazwy produktu w Excelu.
Temat ten omówimy na podstawie przykładowych danych z rys. nr 1.
Rys. nr 1 – przykładowe dane
Jak widać na rysunku powyżej mamy pełne nazwy produktów i wewnątrz nich znajduje się długość poszczególnych przedmiotów (50cm, 35cm itd.), czyli mamy podaną liczbę a za nią oznaczenie cm.
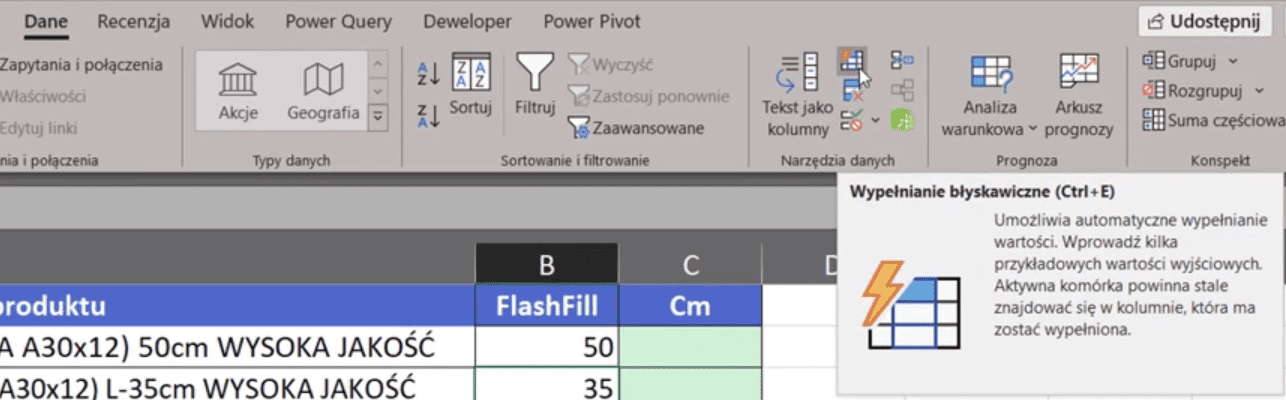
Od Excela 2013 możemy tą informację wyciągnąć za pomocą FlashFill, który działa niejako w tle. Wystarczy, że w pierwszym wierszu napiszemy 50, a w drugim 35. To już powinno wystarczyć, żeby wybrać polecenie Wypełnianie błyskawiczne z karty Dane (rys. nr 2). Ewentualnie możemy skorzystać ze skrótu klawiszowego Ctrl+E.
Rys. nr 2 – polecenie Wypełnianie błyskawiczne
Excel wyciągnie odpowiednie informacje i wypełni pozostałe wiersze, co widać na rys. nr 3.
Rys. nr 3 – działanie Wypełniania błyskawicznego
Jeśli nie masz jeszcze Excela 2013 z opcją FlashFill, to mamy dla Ciebie inne rozwiązanie. Trzeba użyć formuły. Skorzystamy tutaj z tego, że nasza długość ma maksymalnie 3 cyfry, ponieważ w takiej sytuacji łatwo jest wyciągnąć takie informacje. Możemy też zauważyć, że dane które chcemy wyciągnąć poprzedza spacja lub znak -. Pierwszym krokiem będzie odnalezienie tekstu "cm". Użyjemy do tego funkcji SZUKAJ.TEKST, która nie rozróżnia wielkości liter. Pierwszym argumentem funkcji jest szukany_tekst, czyli cm w podwójnych cudzysłowach. Drugi argument funkcji to obejmujący_tekst, czyli tekst, w którym chcemy znaleźć nasze znaki (A2). Zapis formuły powinien wyglądać następująco:
=SZUKAJ.TEKST("cm";A2)
Powyższą formułę zatwierdzamy i kopiujemy w dół. Otrzymamy dane przedstawione na rys. nr 4.
Rys. nr 4 – wyniki funkcji SZUKAJ.TEKST
Otrzymaliśmy liczby, czyli pierwszą pozycję szukanego przez nas tekstu "cm" w całym ciągu znaków. My jednak nie chcemy wyciągać informacji od tego znaku, a przed tym znakiem. Chcemy się cofnąć i wyciągnąć informacje poprzedzające dwuznak cm. Wystarczy, że od tej pozycji, na której się zaczyna ciąg cm odjąć wartość 3, bo nasza liczna ma maksymalnie 3 znaki. Zapis formuły powinien wyglądać następująco:
=SZUKAJ.TEKST("cm";A2)-3
Otrzymamy nowe pozycje o 3 znaki wcześniej przedstawione na rys. nr 5.
Rys. nr 5 – nowa pozycja o 3 znaki wcześniej
Dopiero od tych zmodyfikowanych pozycji chcemy zacząć wyciągać tekst. Użyjemy do tego funkcji FRAGMENT.TEKSTU. Pierwszym argumentem funkcji jest tekst, czyli tekst z którego chcemy wyg=ciągnąć jakiś fragment (A2). Drugi argument funkcji to liczba_początkowa, czyli pozycja od jakiej chcemy zacząć wyciągać informacje (wynik poprzedniej formuły). Trzeci opcjonalny argument to liczba_znaków, czyli ile znaków chcemy wyciągnąć (3). Zapis formuły powinien wyglądać następująco:
=FRAGMENT.TEKSTU(A2;SZUKAJ.TEKST("cm";A2)-3;3)
Powyższą formułę zatwierdzamy. Otrzymamy wyciągnięte dane dotyczące długości poszczególnych produktów przedstawione na rys. nr 6.
Rys. nr 6 – wyciągnięte dane dotyczące długości produktów
Jak łatwo zauważyć na rysunku powyżej, przez to że wyciągnęliśmy 3 znaki, otrzymaliśmy część danych poprzedzonych minusem lub spacją. Musimy te dodatkowe znaki usunąć. Wystarczy dołożyć jedną funkcję. Zanim jednak to zrobimy, musimy zwrócić uwagę, że nasze dane to według Excela tekst, a nie wartości liczbowe, bo są wyrównane do lewej strony. Wynika to z użycia funkcji FRAGMENT.TEKSTU, która jest funkcją tekstową i zwraca tekst. Musimy użyć tutaj funkcji matematycznej MODUŁ.LICZBY, która konwertuje tekst na liczbę, jak również usuwa znak minus i spację sprzed liczby. Zapis formuły powinien wyglądać następująco: