W tym poście omówimy wyszukiwanie po dwóch lub więcej kryteriach. Ze względu na nową funkcję w Excelu tablicowym przedstawimy 4 różne sposoby rozwiązania takiego problemu.
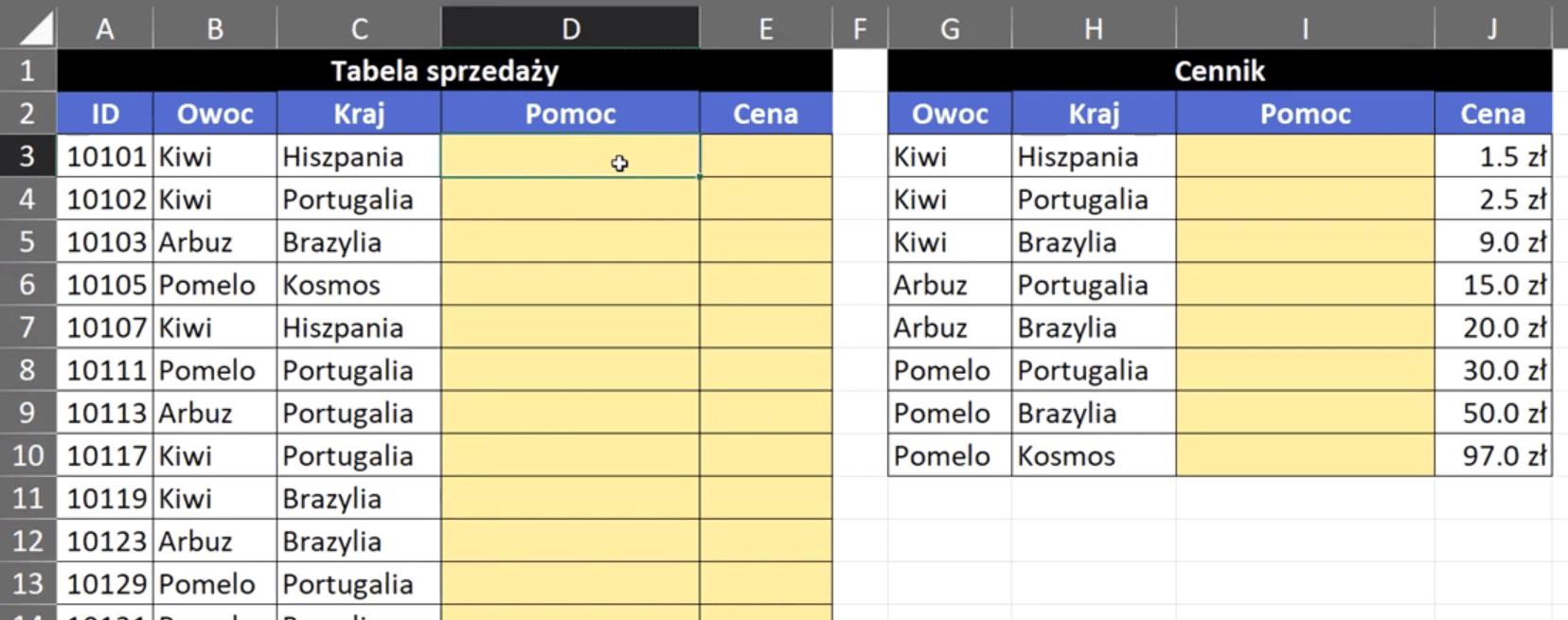
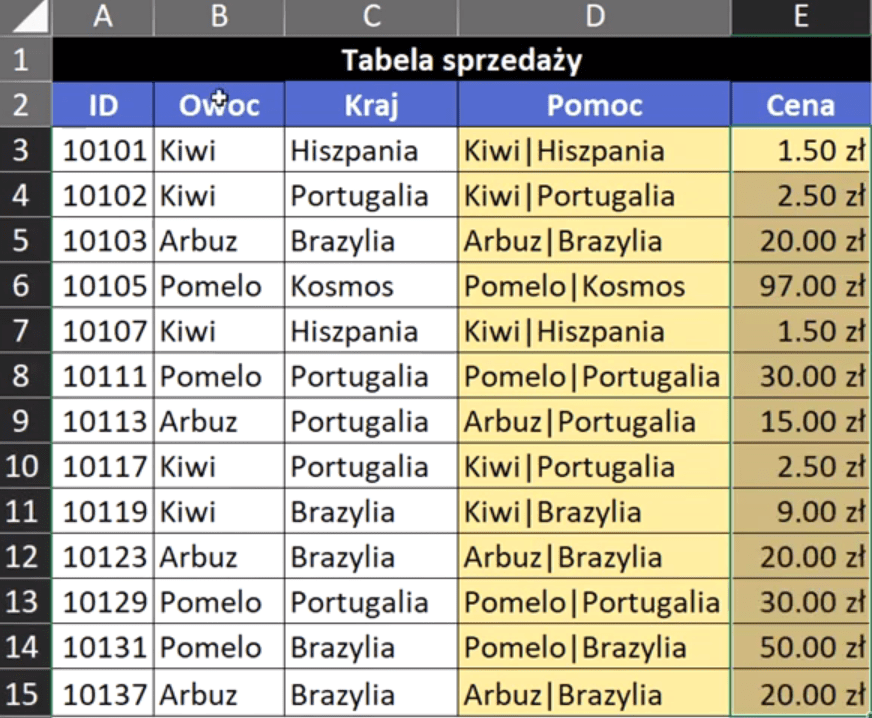
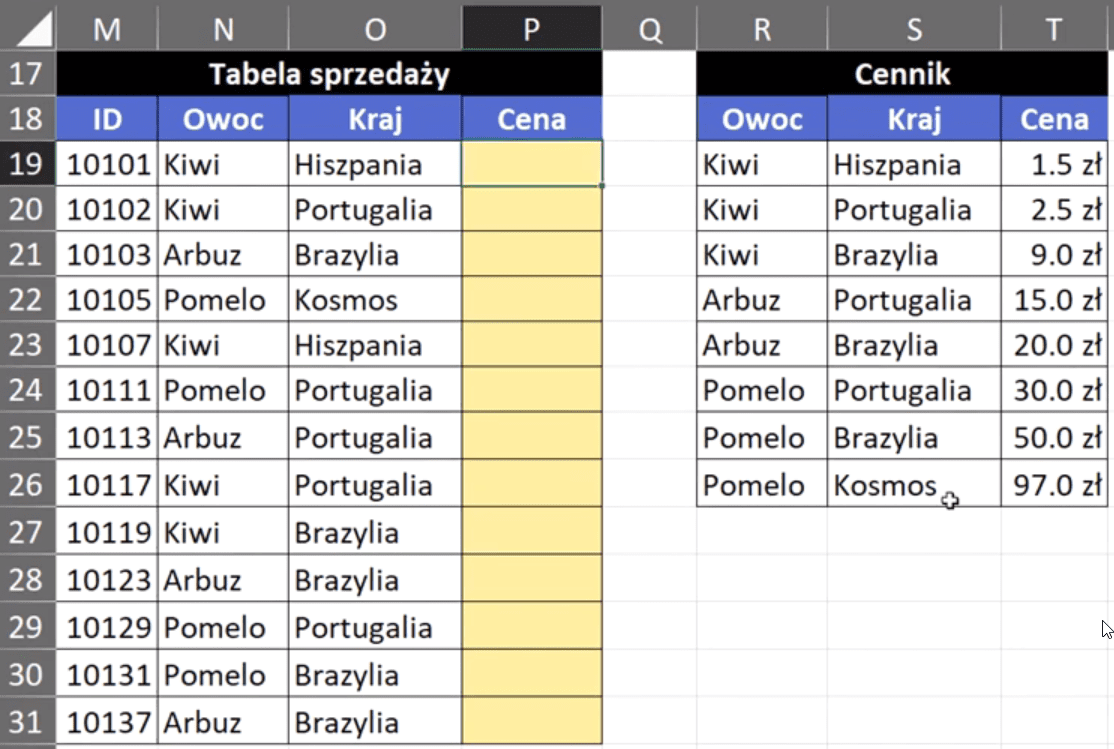
Problem polega na tym, że cena produktu zależy nie tylko od nazwy produktu, ale również od kraju, z jakiego pochodzi ten produkt. Musimy wyszukać cenę produktu po 2 kryteriach. Pierwsze rozwiązanie wykorzystuje kolumnę pomocniczą (rys. nr 1).
Rys. nr 1 – przykładowe dane do pierwszego rozwiązania
Musimy napisać formułę, w której połączymy nazwę owocu z krajem jego pochodzenia. Użyjemy do tego znaku ampersand (&) i pionowej kreski (|), aby na pewno rozdzielić dwa ciągi tekstowe. Zapis formuły powinien wyglądać następująco:
=B3&"|"&C3
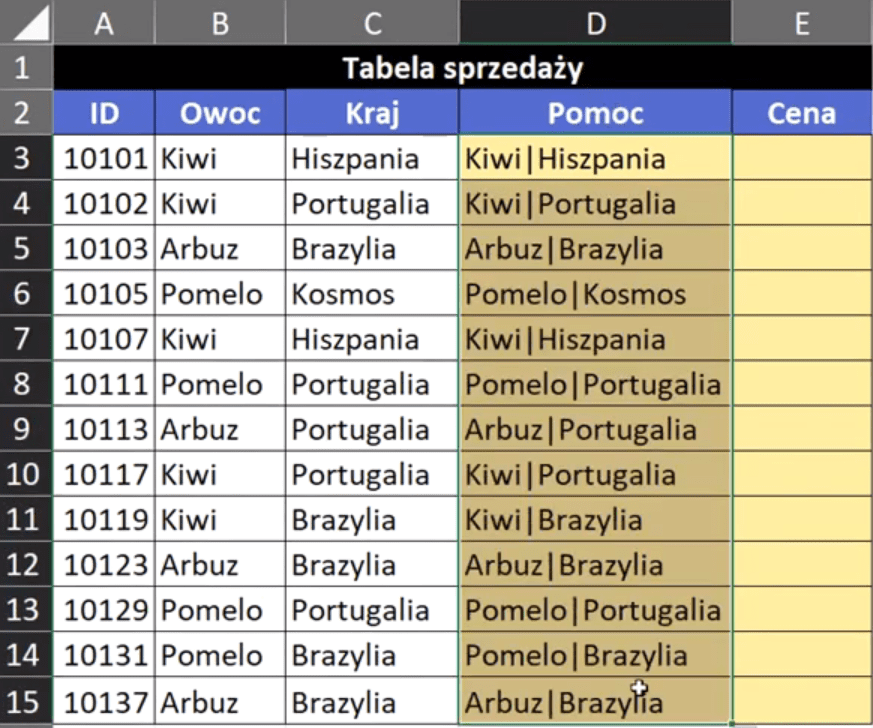
Po zatwierdzeniu formuły i przeciągnięciu jej na komórki poniżej otrzymamy dane przedstawione na rys. nr 2.
Rys. nr 2 – połączone dane z dwóch kolumn (Owoc i Kraj)
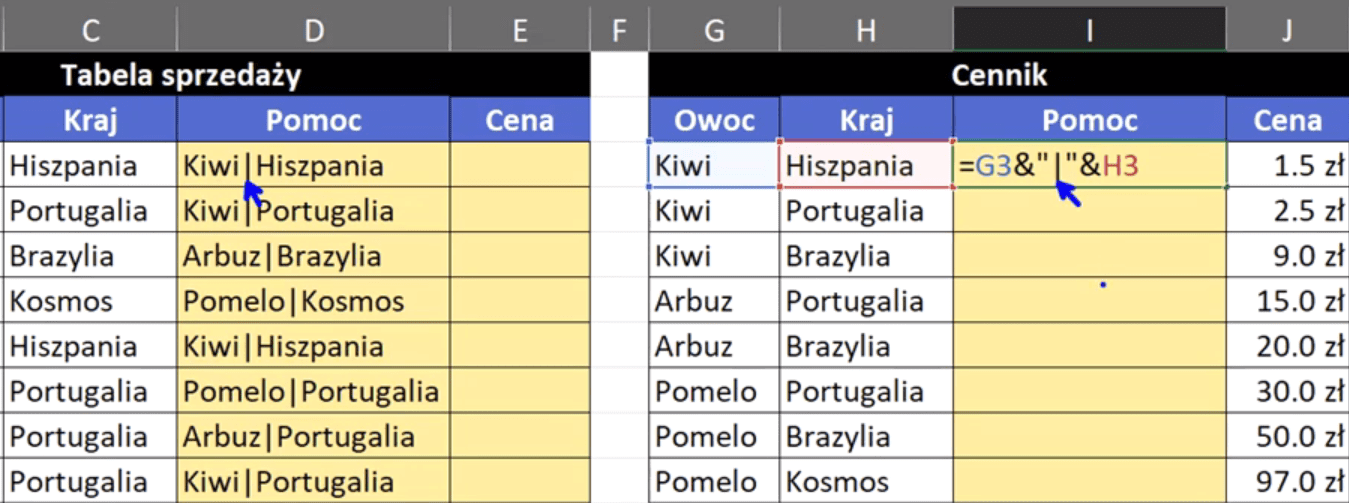
Otrzymaliśmy połączone niejako dane z pierwszej i drugiej kolumny rozdzielone pionową kreską. Dla Excela nie jest to potrzebne, ale my mamy lepszą wizualną formę danych. Mamy pomocniczą kolumnę z połączoną informacją i teraz możemy skopiować z niej formułę za pomocą skrótu klawiszowego Ctrl+C i wkleić w kolumnę pomocniczą z Cennikiem. Istotne jest tutaj, że zarówno dane z naszej Tabeli sprzedaży jak i w Cenniku muszą mieć ten znak rozdzielający (pionową kreskę) – rys. nr 3.
Rys. nr 3 – pionowa kreska rozdzielająca nazwę owocu i jego kraj pochodzenia w obu tabelach
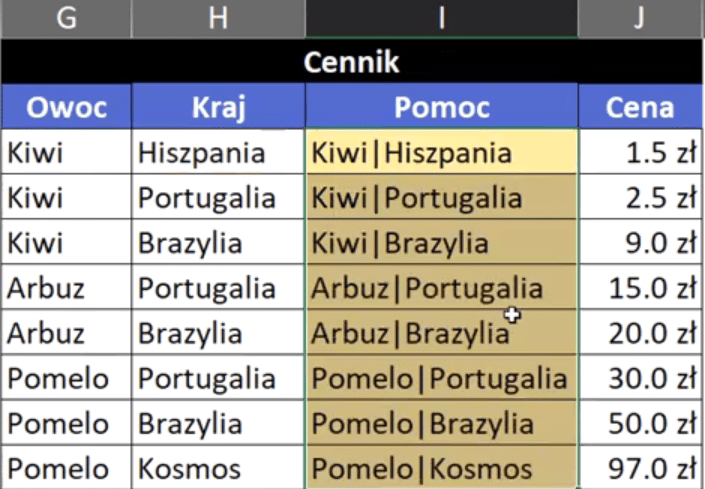
Po wklejeniu formuły do komórki I3, zatwierdzamy ją i kopiujemy na komórki poniżej. Otrzymamy dane przedstawione na rys. nr 4.
Rys. nr 4 – wypełniona kolumna pomocnicza w Cenniku
Teraz musimy wyszukać tylko jedną informację (połączone dwie wartości), dlatego możemy skorzystać ze standardowej funkcji WYSZUKAJ.PIONOWO. Pierwszym argumentem funkcji jest szukana_wartość, czyli dane z kolumny Pomoc z Tabeli sprzedażowej. Drugi argument funkcji to tabela_tablica, czyli kolumny Pomoc i Cena z tabeli Cennik (zablokowane bezwzględnie). Trzeci argument to nr_indeksu_kolumny, czyli u nas wartość 2, bo chcemy wyciągnąć informację z kolumny Cena, która jest druga w kolejności z zakresu tabela_tablica. Ostatni argument (opcjonalny) to przeszukiwany_zakres, w którym musimy zdecydować, czy robimy wyszukiwanie przybliżone, czy dokładne. W większości sytuacji chcemy mieć dopasowanie dokładne, bo nie mamy pewności, czy dane są posortowane, czyli wpisujemy wartość logiczną FAŁSZ lub wartość z nią tożsamą (0). Zapis formuły powinien wyglądać następująco:
=WYSZUKAJ.PIONOWO(D3;$I$3:$J$10;2;0)
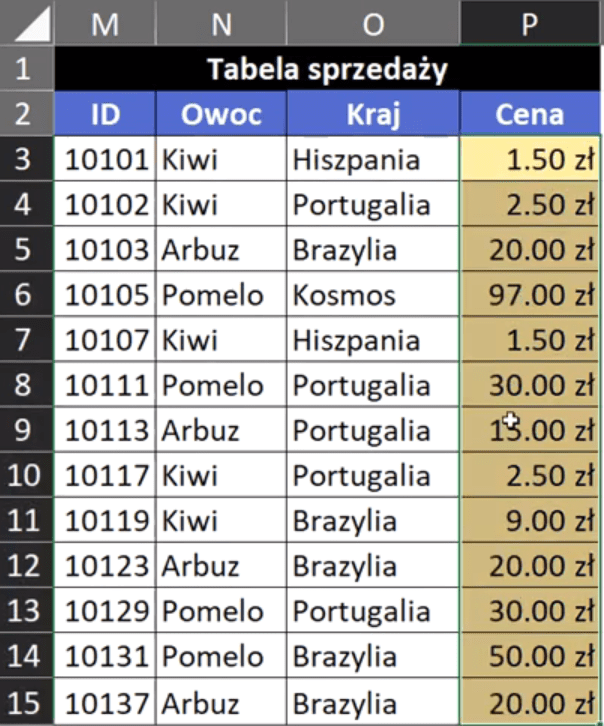
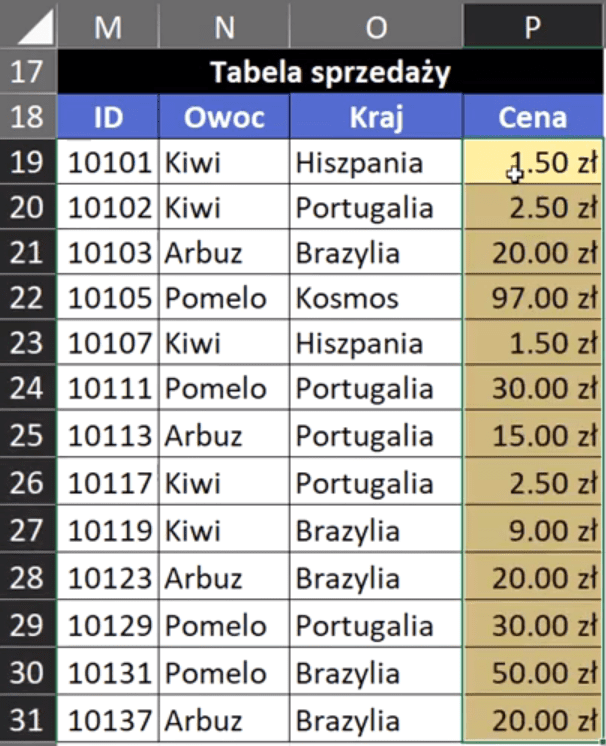
Powyższą formułę zatwierdzamy i kopiujemy w dół. Otrzymamy dane z dopasowaną ceną według dwóch kryteriów przedstawione na rys. nr 5.
Rys. nr 5 — dane z dopasowaną ceną według dwóch kryteriów (pierwszy sposób – Excel klasyczny)
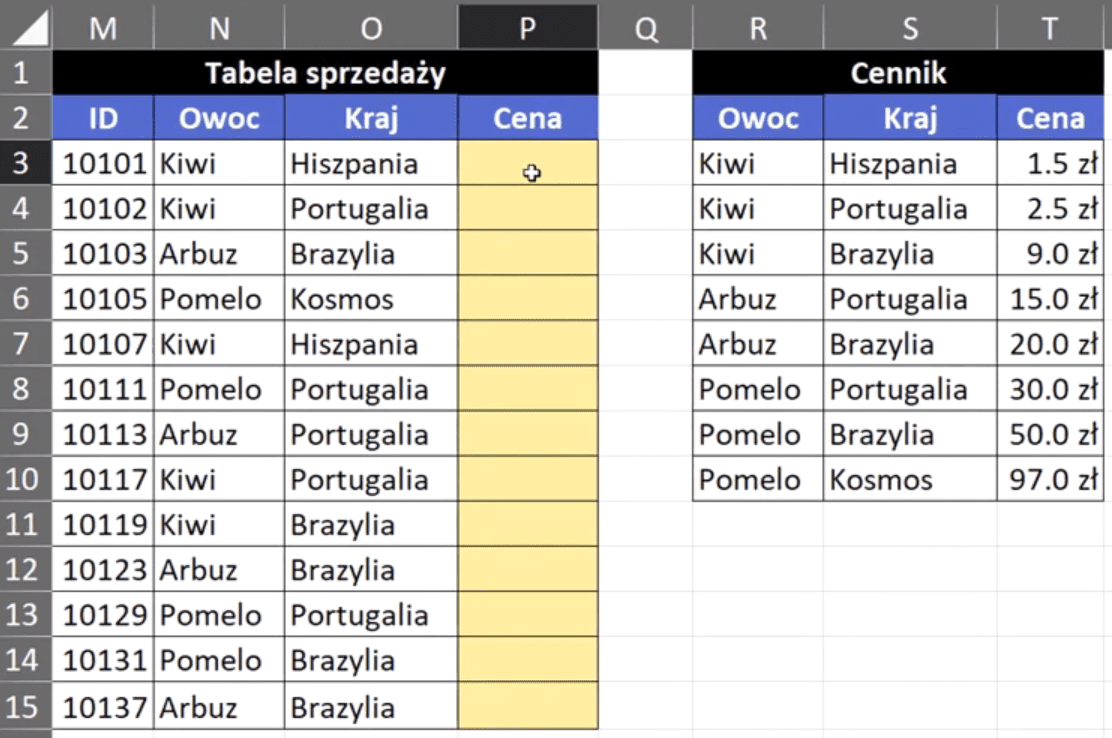
Teraz omówimy drugie rozwiązanie, które również będzie niejako wykorzystywało kolumnę pomocniczą, ale zbudowaną wewnątrz funkcji. Rozwiązanie to omówimy na podstawie przykładowych danych z rys. nr 6.
Rys. nr 6 przykładowe dane do rozwiązanie drugim sposobem
W klasycznym Excelu mogliśmy użyć funkcji PODAJ.POZYCJĘ. Pierwszym argumentem funkcji jest szukana_wartość, w którym szukamy owocu połączonego z krajem pochodzenia za pomocą znaku ampersand (&). Drugi argument to przeszukiwana_tab, czyli znowu dwie połączone za pomocą znaku & kolumny tym razem z tabeli Cennik zablokowane bezwzględnie. Jeśli na tym etapie podejrzymy wyniki formuły za pomocą klawisza F9, zobaczymy połączone dane z obu kolumn (rys. nr 7).
Rys. nr 7 – podejrzane wyniki formuły w trybie edycji komórki
Wychodzimy z podglądu wyników formuły za pomocą skrótu klawiszowego Ctrl+Z. Pozostaje nam ostatni argument, czyli typ_porównania. U nas będzie to wartość 0 odpowiadająca dopasowaniu dokładnemu. Zapis formuły powinien wyglądać następująco:
=PODAJ.POZYCJĘ(N3&O3;$R$3:$R$10&$S$3:$S$10;0)
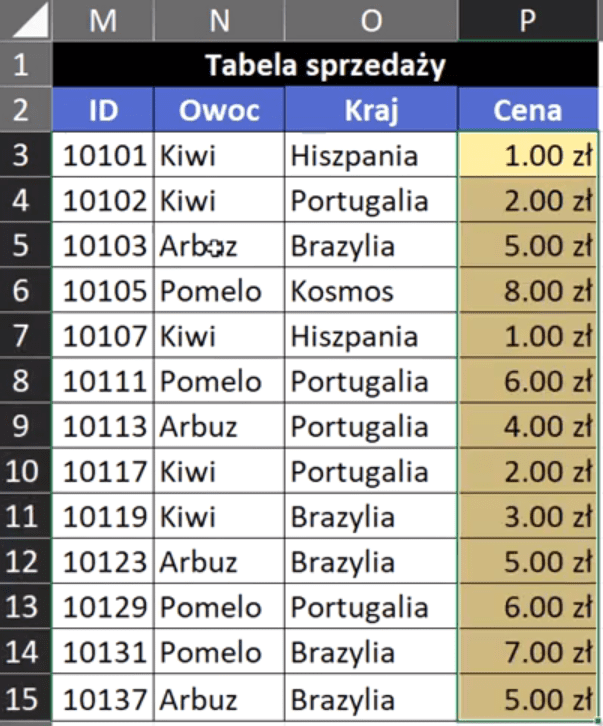
Powyższą formułę zatwierdzamy i kopiujemy w dół. Pokazują nam się wartości w złotówkach, ale to tylko dlatego, że mamy sformatowaną kolumnę walutowo. Tak naprawdę pokazuje nam się pozycja szukanej ceny (rys. nr 8).
Rys. nr 8 – pozycje szukanych cen sformatowane walutowo
Mamy znalezioną pozycję właściwej ceny. Teraz na podstawie tej pozycji musimy wyszukać pasującą cenę. Taki efekt możemy uzyskać za pomocą funkcji INDEKS. Pierwszym argumentem funkcji jest tablica, czyli kolumna, z której chcemy dostać zwróconą cenę zablokowana bezwzględnie. Drugi argument funkcji to nr_wiersza, czyli wynik naszej funkcji PODAJ.POZYCJĘ. Zapis formuły powinien wyglądać następująco:
Powyższą formułę zatwierdzamy i kopiujemy na komórki poniżej. Otrzymamy ceny produktów wyszukane według 2 kryteriów przedstawione na rys. nr 9.
Rys. nr 9 — ceny produktów wyszukane według 2 kryteriów (drugi sposób – Excel klasyczny)
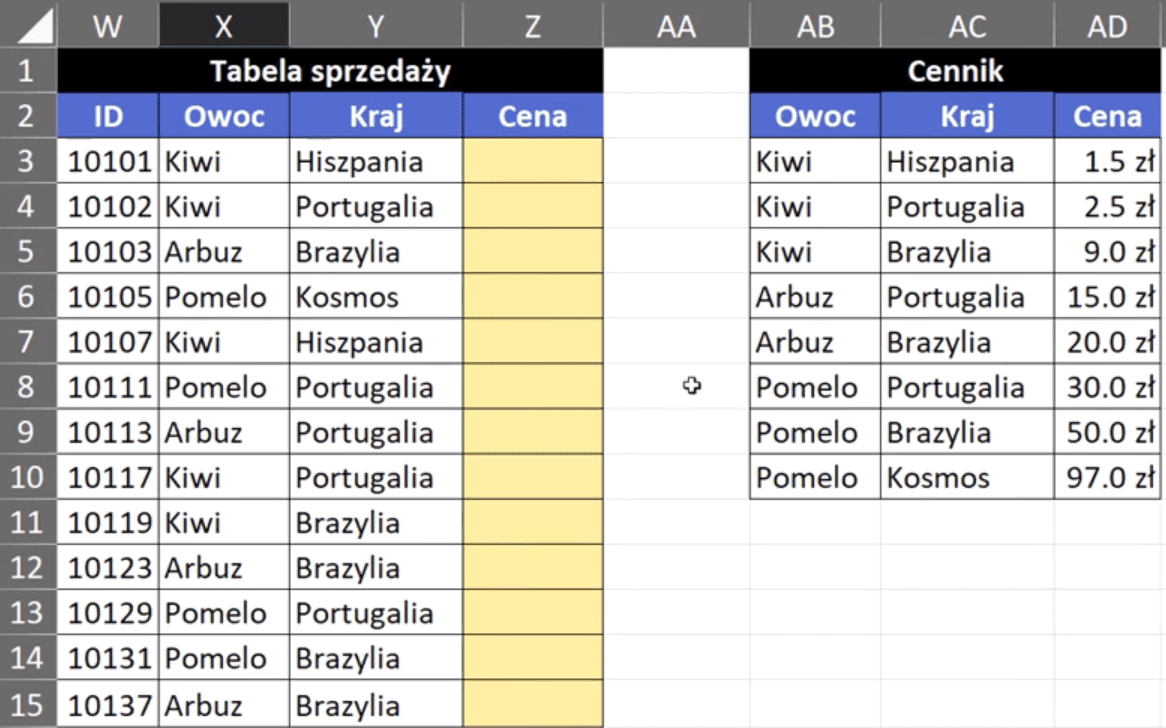
Trzecie rozwiązanie wykonamy w Excelu tablicowym. Przykładowe dane do tego zadania zostały przedstawione na rys. nr 10.
Rys. nr 10 – przykładowe dane do rozwiązania w Excelu tablicowym (trzecie rozwiązanie)
Wykorzystamy tutaj funkcję X.WYSZUKAJ. Pierwszym argumentem funkcji jest szukana_wartość, czyli połączone dwie wartości z kolumny Owoc i Kraj za pomocą znaku & z Tabeli sprzedażowej. Drugi argument funkcji to szukana_tablica, czyli połączone kolumny Owoc i Kraj za pomocą znaku &, ale z tabeli Cennik i zablokowane bezwzględnie. Kolejny argument to zwracana_tablica, czyli wartości z kolumny Cena z tabeli Cennik zablokowane bezwzględnie. Funkcja X.WYSZUKAJ działa na zasadzie dopasowania dokładnego, więc nie musimy podawać argumentów opcjonalnych. Zapis formuły powinien wyglądać następująco:
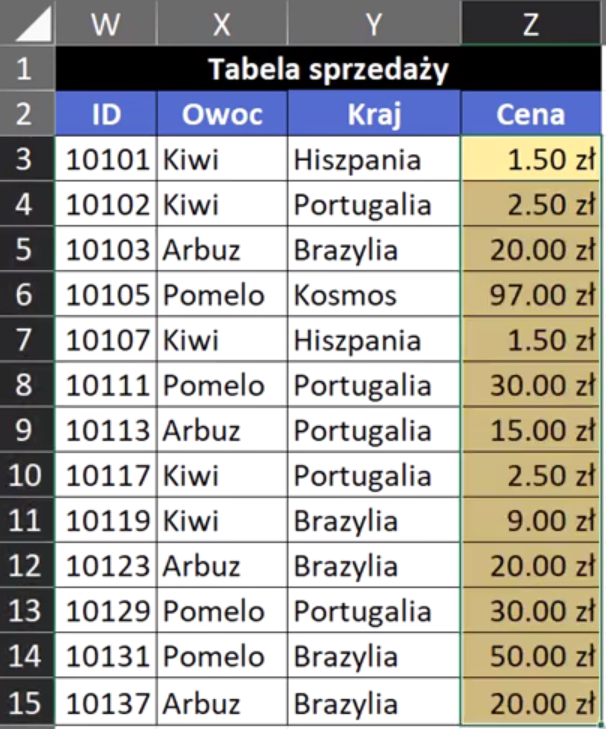
Powyższą formułę zatwierdzamy i kopiujemy w dół. Otrzymamy ceny wyszukane na podstawie 2 kryteriów przedstawione na rys. nr 11.
Rys. nr 11 — ceny wyszukane na podstawie 2 kryteriów (trzeci sposób – Excel tablicowy)
Pozostało nam czwarte rozwiązanie, w którym będziemy bazować na tym, jak się nasze dane układają i jak często się powtarzają. Przykładowe dane zostały przedstawione na rys. nr 12.
Rys. nr 12 – przykładowe dane (czwarte rozwiązanie)
Możemy łatwo zauważyć, że każdy wiersz z tabeli Cennik jest unikatowy, czyli występuje tylko 1 raz. Na tej podstawie w tym rozwiązaniu możemy wykorzystać całkiem inną funkcję niż funkcje wyszukujące, których do tej pory używaliśmy. Wykorzystamy funkcję SUMA.WARUNKÓW. Pierwszym argumentem funkcji jest suma_zakres, czyli u nas kolumna z Ceną z tabeli Cennik zablokowana bezwzględnie za pomocą klawisza F4. Drugi argument funkcji to kryteria_zakres1, czyli zakres, na którym budujemy pierwsze kryterium – kolumna Owoc z tabeli Cennik zablokowana bezwzględnie. Kolejny argument to kryteria1, czyli dane z kolumny Owoc z Tabeli sprzedażowej. Kolejny argument to kryteria_zakres2, czyli drugie kryterium – kolumna Kraj z tabeli Cennik zablokowana bezwzględnie. I ostatni argument kryteria2, czyli wartość z kolumny Kraj z Tabeli sprzedażowej. Zapis formuły powinien wyglądać następująco:
Powyższą formułę zatwierdzamy i kopiujemy w dół. Otrzymamy ceny ustalone według 2 kryteriów przedstawione na rys. nr 13.
Rys. nr 13 – ceny ustalone na podstawie 2 kryteriów (czwarte rozwiązanie)
Jak widać powyżej możemy to samo zadanie wykonać w Excelu na kilka sposobów, wykorzystując różne funkcje. Każde z przedstawionych rozwiązań zwróciło te same wartości. Do nas należy decyzja i ocena, które rozwiązanie jest najlepsze czy najszybsze.
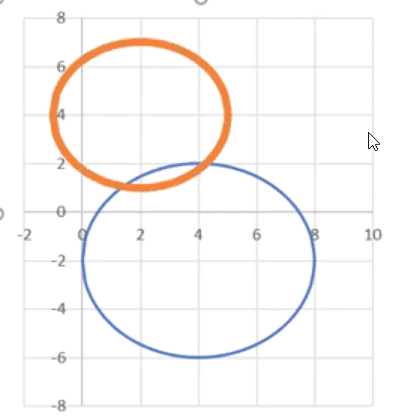
W tym poście nauczymy się, jak wstawić dwa okręgi na wykresie punktowym albo tak naprawdę dowolne kształty.
Zaczniemy od tego, że równanie okręgu o środku w punkcie (0,0) powinno wyglądać następująco: X2+Y2=R2, gdzie X,Y to współrzędne środka okręgu, a R to promień.
Temat ten omówimy na podstawie przykładowych danych z rys. nr 1.
Rys. nr 1 – przykładowe dane
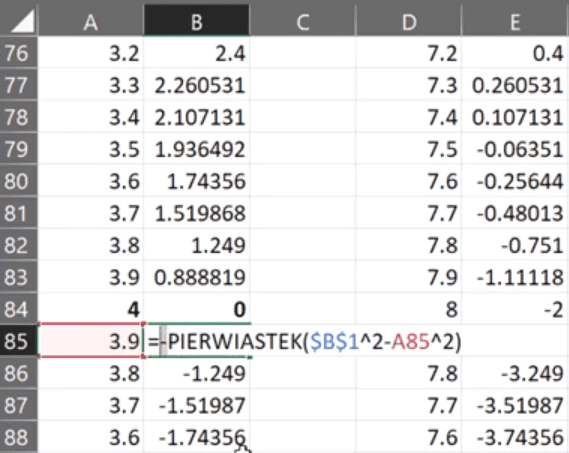
Na potrzeby Excela potrzebujemy odpowiednią ilość punktów (ich współrzędnych X i Y). Najpierw zakładamy sobie wartość promienia naszego okręgu i generujemy ciąg wartości X, następnie za pomocą funkcji PIERWIASTEK musimy obliczyć współrzędną Y. Wystarczy przekształcić wyżej podany wzór. Zapis formuły powinien wyglądać następująco:
=PIERWIASTEK($B$1^2-A4^2)
Ponieważ nasz okrąg jest jak sama nazwa wskazuje okrągły to dla każdej wartości X ma dwie wartości Y. Wyznaczamy sobie wartości dla X od ‑4 do 4. Następnie musimy wyznaczyć wartości przeciwne, czyli do naszej formuły musimy dołożyć na początku znak minus (rys. nr 2). Wynika to z wyliczania pierwiastka.
Rys. nr 2 – dołożony znak minus przed formułą
Ponadto musi być zachowana kolejność, czyli najpierw nasze wartości X rosną (od ‑4 do 4), a następnie maleją (od 4 do ‑4). Na potrzeby Excela wystarczy przeskok wartości punktów o 0,1.
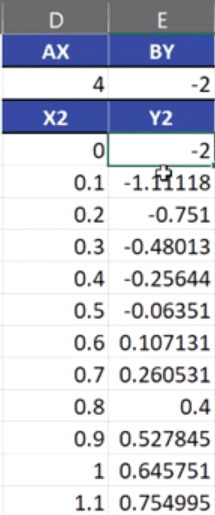
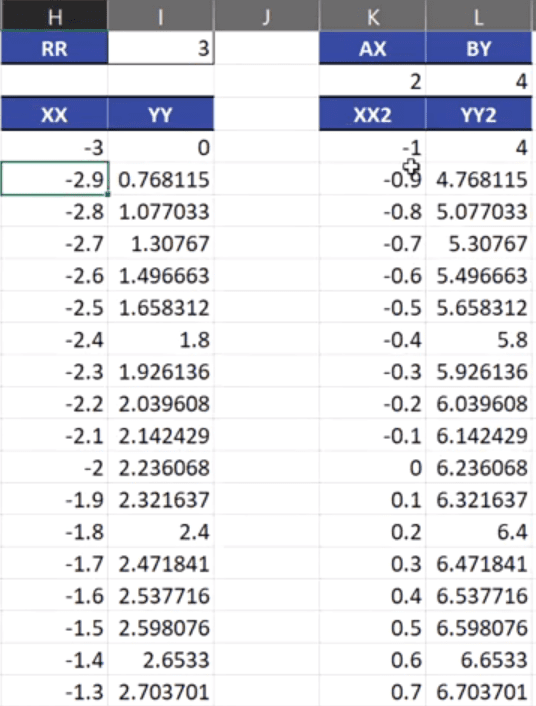
Po obliczeniu potrzebnych punktów, możemy do wykresu dodać parametr A i B, które spowodują przesunięcie naszego wykresu względem środka układu współrzędnych, czyli punktu (0,0). O wartość parametru AX przesunie się środek koła w poziomie, a o wartość parametru BY przesunie się w pionie. Współrzędne koła uwzględniające przesunięcie zostały przedstawione na rys. nr 3.
Rys. nr 3 — współrzędne koła uwzględniające przesunięcie
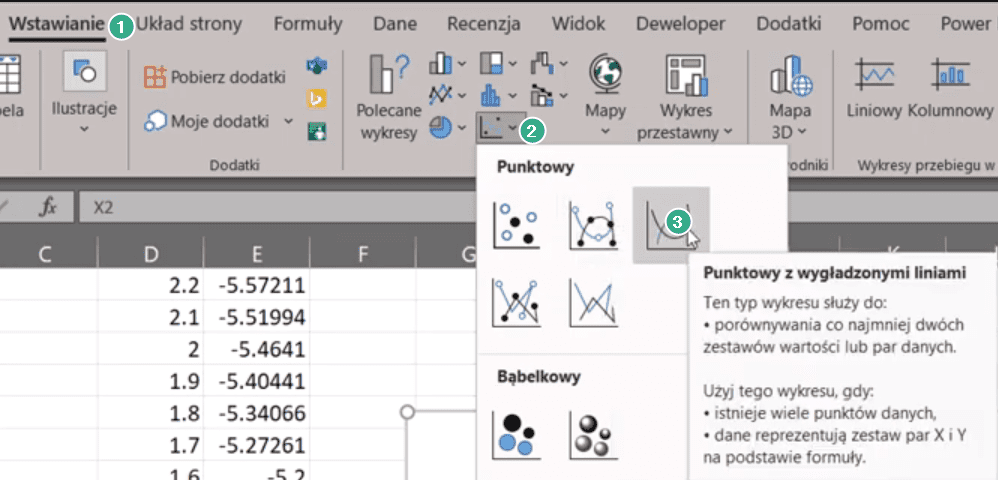
Zaznaczamy zakres współrzędnych X2 i Y2 do końca danych za pomocą skrótu klawiszowego Ctrl+Shift+Strzałka w dół, następnie rozwijamy grupę poleceń wykresów punktowych (punkt 2 na rys. nr 4) z karty Wstawianie (punkt 1) i wybieramy wykres punktowy z wygładzonymi liniami (punkt 3).
Rys. nr 4 – wstawianie wykresu punktowego
Excel wstawi automatyczny wykres, który później będziemy edytować na nasze potrzeby (rys. nr 5).
Rys. nr 5 – automatycznie wstawiony wykres punktowy z wygładzonymi liniami
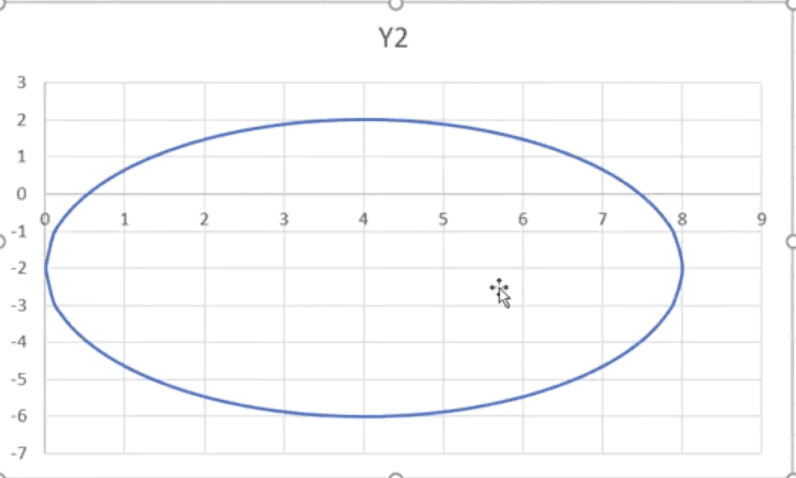
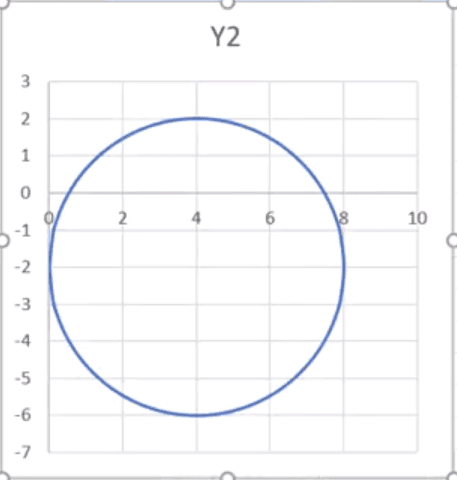
Przede wszystkim musimy ręcznie zmienić wielkość w poziomie tak, aby jednostki w poziomie pokrywały się z wielkością jednostek pionowych (aby otrzymać koło a nie elipsę) – rys. nr 6.
Rys. nr 6 – wykres po zmianie wielkości
Analogicznie w danych obok mamy obliczone współrzędne drugiego okręgu i jego współrzędne po przesunięciu środka. Podany jest również promień, po czym widać, że będzie ono mniejsze (rys. nr 7).
Rys. nr 7 – współrzędne drugiego okręgu
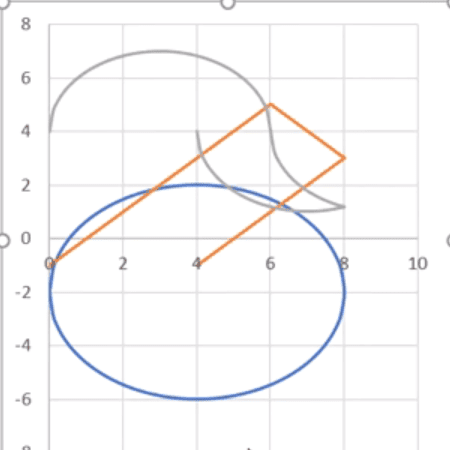
Punkty te chcemy dołożyć do naszego wykresu, czyli drugi okrąg. Zaznaczamy kolejną partię danych, czyli współrzędnych okręgu z przesunięciem XX2 i YY2, następnie kopiujemy je za pomocą skrótu klawiszowego Ctrl+C, zaznaczamy nasz wykres i dopiero wtedy wklejamy dane za pomocą skrótu klawiszowego Ctrl+V. Otrzymamy coś dziwnego, bo niestety po takim wklejeniu dodatkowych punktów Excel głupieje i wstawia jakieś dziwne kształty (rys. nr 8).
Rys. nr 8 – wykres po dodaniu nowych współrzędnych
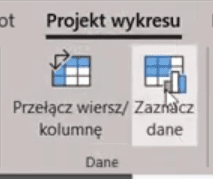
Wynika to z tego, że Excel pamięta wcześniejszą serię danych i dlatego każde nowe dodane punkty traktuje jako nową serię. Przez to wychodzą takie dziwne kształty, pomarańczowy kolor to wartości X a szare to Y. Wracamy do stanu sprzed wklejenia punktów za pomocą skrótu klawiszowego Ctrl+Z. Aby poradzić sobie z tym problemem, musimy przejść do karty Projekt wykresu i wybrać polecenie Zaznacz dane (rys. nr 9).
Rys. nr 9 – polecenie Zaznacz dane
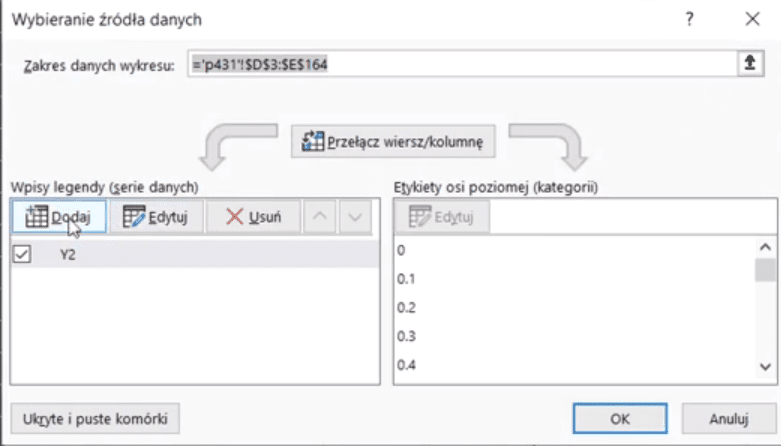
Musimy sami ręcznie zaznaczyć odpowiednie dane. Otworzy nam się okno Wybieranie źródła danych, gdzie w polu Wpisy legendy (serie danych) klikamy przycisk Dodaj (rys. nr 10).
Rys. nr 10 – okno Wybierania źródła danych
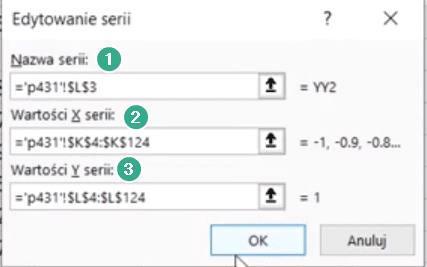
Otworzy nam się okienko Edytowania serii, gdzie w polu Nazwa serii (punkt 1 na rys. nr 11) zaznaczamy komórkę z nazwą YY2 (L3), następnie w polu Wartość X serii (punkt 2) zaznaczamy dane z zakresu K4:K124 i w polu Wartość Y serii (punkt 3) zaznaczamy zakres L4:L124. Podane serie zatwierdzamy przyciskiem OK.
Rys. nr 11 – okno Edytowania serii
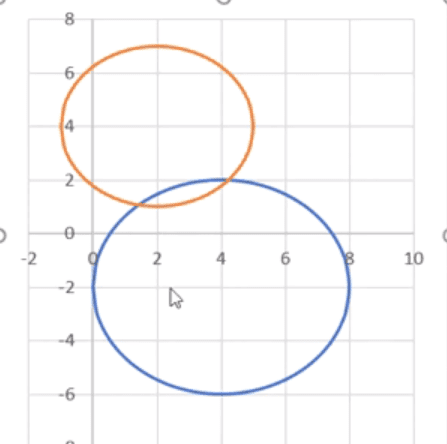
Excel wróci do okna Wybierania źródła danych, które zatwierdzamy przyciskiem OK. Otrzymamy Wykres przedstawiony na rys. nr 12.
Rys. nr 12 – wykres dwóch okręgów
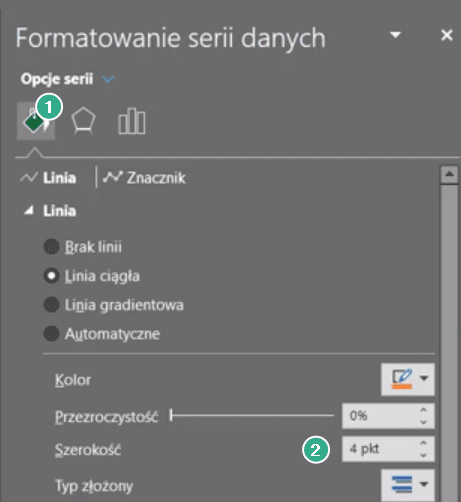
Jeśli potrzebujemy coś zmienić na naszym wykresie, to zaznaczamy jeden okrąg i za pomocą skrótu klawiszowego Ctrl+1, uruchamiamy okno Formatowania serii danych, gdzie w Wypełnieniach (punkt 1 na rys. nr 13) możemy zmienić Szerokość linii (punkt 2).
Rys. nr 13 – zmiana szerokości linii wykresu
Otrzymamy pogrubioną linię zaznaczonego wykresu przedstawioną na rys. nr 14.
Rys. nr 14 – wykres po zmianie szerokości linii
Podstawą do wykonania takich wykresów jest przygotowanie listy punktów (współrzędnych). Jeśli nasz wykres jest bardziej okrągły to wybieramy wykres punktowy o wygładzonych liniach, a jeśli jest kanciasty (trójkąt itp.) to wybieramy wykres z prostymi liniami. Ponadto przy wykresach z liniami prostymi wystarczy mniej punktów, żeby się dobrze prezentował.
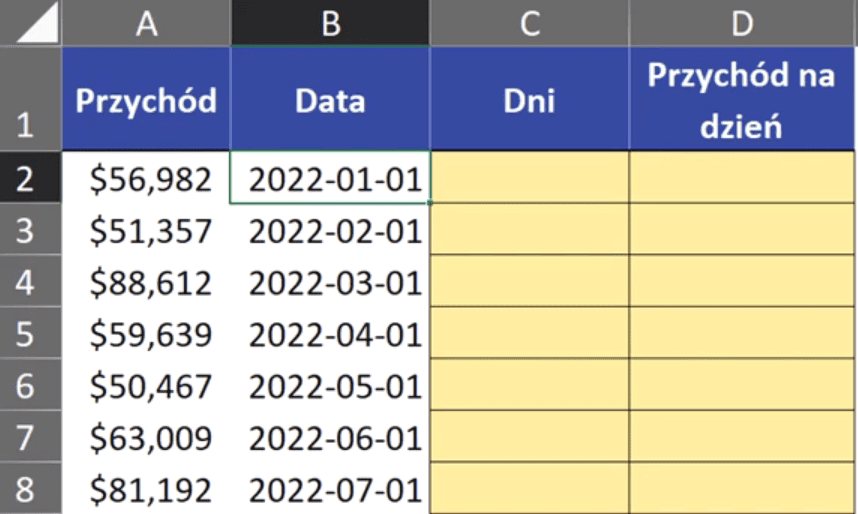
W tym poście nauczymy się, jak obliczyć liczbę dni w miesiącu.
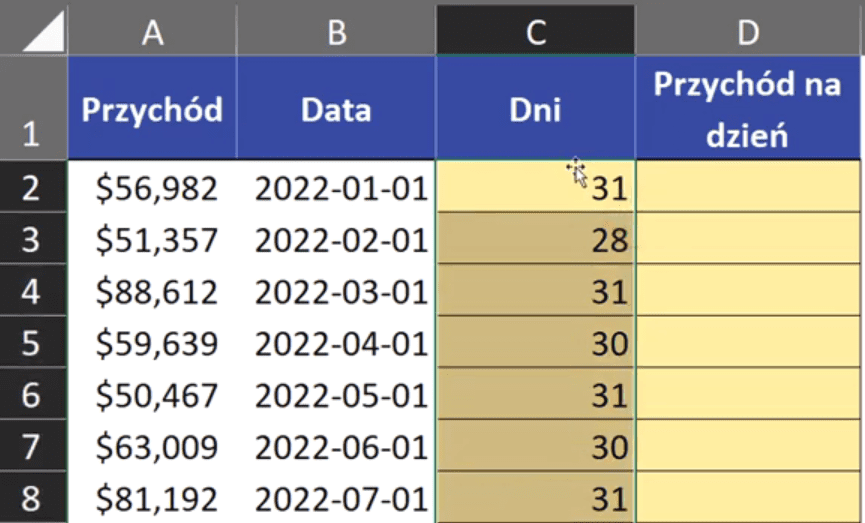
Temat ten omówimy na podstawie przykładowych danych z rys. nr 1.
Rys. nr 1 – przykładowe dane
Aby najłatwiejszym sposobem obliczyć ilość dni w miesiącu, wystarczy sprawdzić, jaki numerek przypada na ostatni dzień tego miesiąca. W przykładowych danych mamy przychody i daty, które odpowiadają poszczególnym miesiącom. Nasze zadanie polega na obliczeniu przychodu, jaki przypada na jeden dzień miesiąca, inaczej dzienny przychód. Zaczynamy od tego, że na podstawie daty musimy wyznaczyć ostatni dzień tego miesiąca. Możemy do tego użyć funkcji NR.SER.OST.DN.MIES. Pierwszym argumentem funkcji jest data_pocz, czyli nasza data z danych (nie musi to być pierwszy dzień miesiąca). Drugi argument funkcji to miesiące, czyli podajemy, o ile miesięcy chcemy się przesunąć, aby zobaczyć ostatni dzień miesiąca (jeśli wpiszemy wartość 0, otrzymamy ostatni dzień miesiąca, z którego podamy dowolną datę). Zapis formuły powinien wyglądać następująco:
=NR.SER.OST.DN.MIES(B2;0)
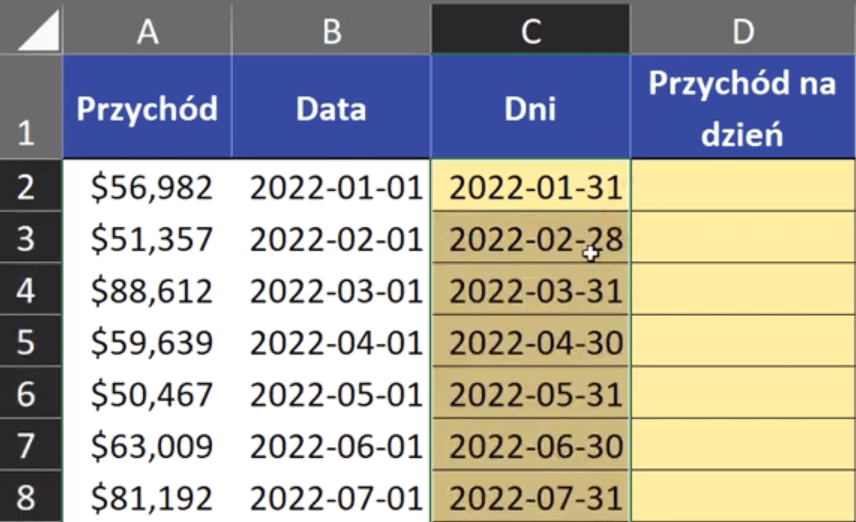
Powyższą formułę zatwierdzamy i kopiujemy na komórki poniżej. Otrzymamy dane przedstawiające ostatni dzień danego miesiąca (rys. nr 2).
Rys. nr 2 – data z ostatnim dniem miesiąca
Teraz musimy użyć funkcji DZIEŃ, która zwraca dzień miesiąca od 1 do 31. Argumentem funkcji jest kolejna_liczba, czyli nasza data ostatniego dnia miesiąca. Zapis formuły powinien wyglądać następująco:
=DZIEŃ(NR.SER.OST.DN.MIES(B2;0))
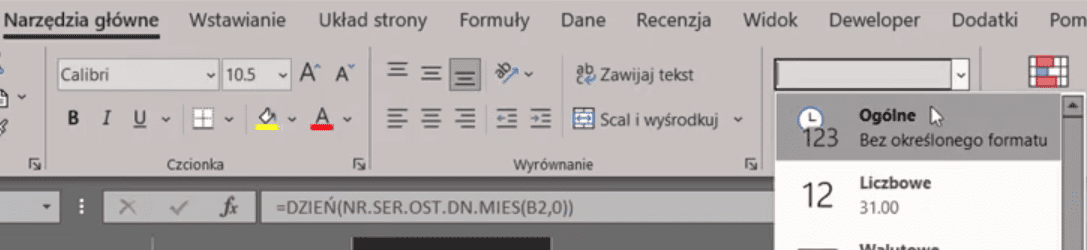
Powyższą formułę zatwierdzamy i kopiujemy w dół. Musimy pamiętać o zmianie formatowania komórek na Ogólne na karcie Narzędzia główne w grupie poleceń Liczba (rys. nr 3).
Rys. nr 3 – zmiana formatowania komórek
Po zmianie formatowania otrzymamy ilość dni w poszczególnych miesiącach przedstawioną na rys. nr 4.
Rys. nr 4 – ilość dni w poszczególnych miesiącach
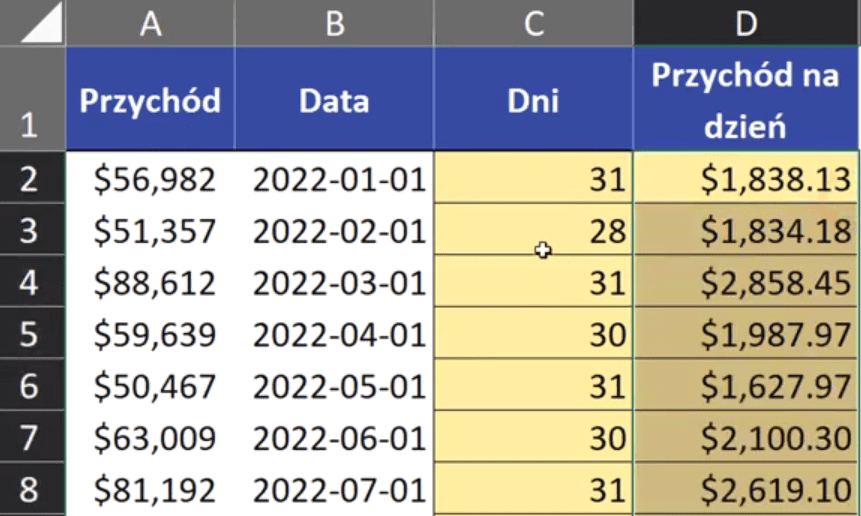
Teraz pozostaje nam obliczyć wartość przychodu przypadającą na jeden dzień. Wystarczy podzielić Przychód przez ilość dni. Zapis formuły powinien wyglądać następująco:
=A2/C2
Po zatwierdzeniu formy i skopiowaniu jej na komórki poniżej otrzymamy dzienny przychód przedstawiony na rys. nr 5.
Rys. nr 5 – dzienny przychód
Tym sposobem możemy również sprawdzić, czy dany rok jest przestępny (luty powinien wtedy mieć 29 dni).
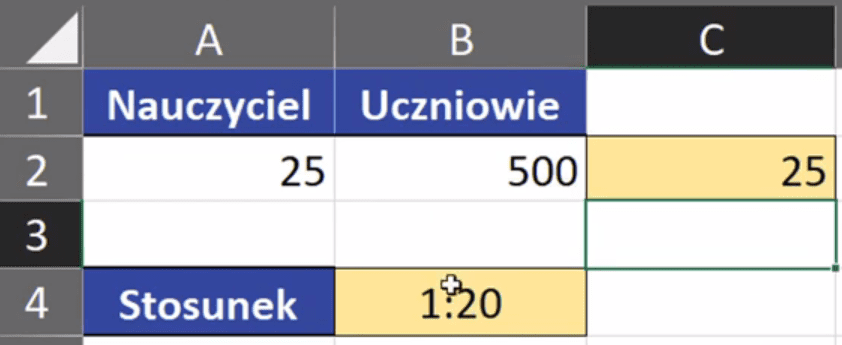
W tym poście nauczymy się, jak napisać stosunek dwóch liczb.
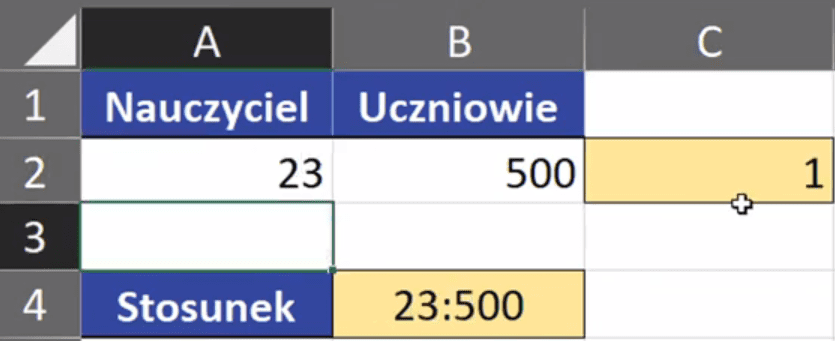
Zadanie to wykonamy na podstawie przykładowych danych z rys. nr 1.
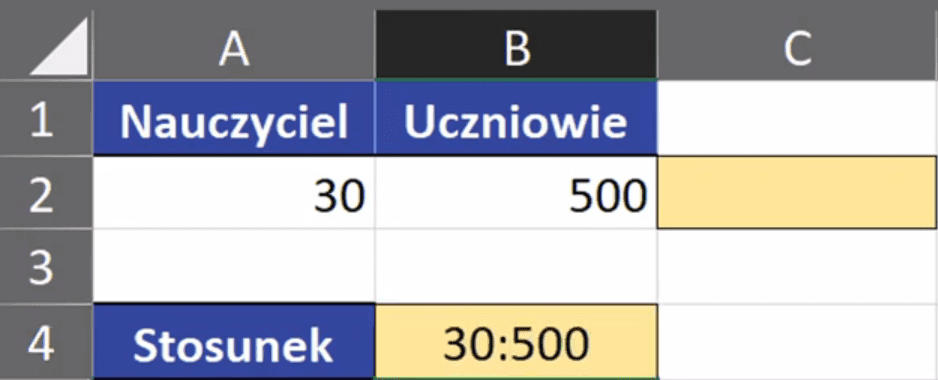
Rys. nr 1 – przykładowe dane
W tym zadaniu chcemy przedstawić stosunek liczby nauczycieli do ilości uczniów. Poza Excelem taki stosunek zapisalibyśmy jako 30:500. Jednak po zatwierdzeniu takiego zapisu Excel nie reaguje (rys. nr 2).
Rys. nr 2 – nieprawidłowo zapisany stosunek dwóch liczb
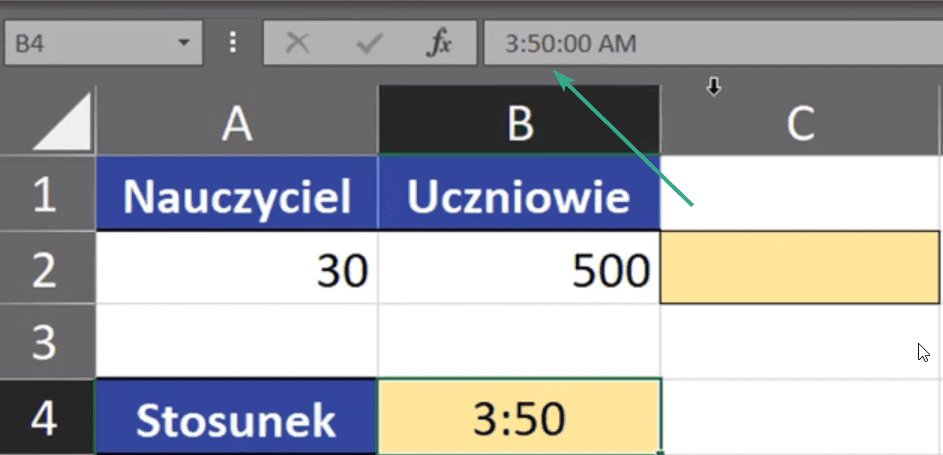
Jak widać powyżej liczby te możemy skrócić i zapisać je jako stosunek 3:50. Jednak wtedy Excel zamienia ten stosunek na czas, co widać na pasku formuły (rys. nr 3).
Rys. nr 3 – zamiana stosunku liczb na czas
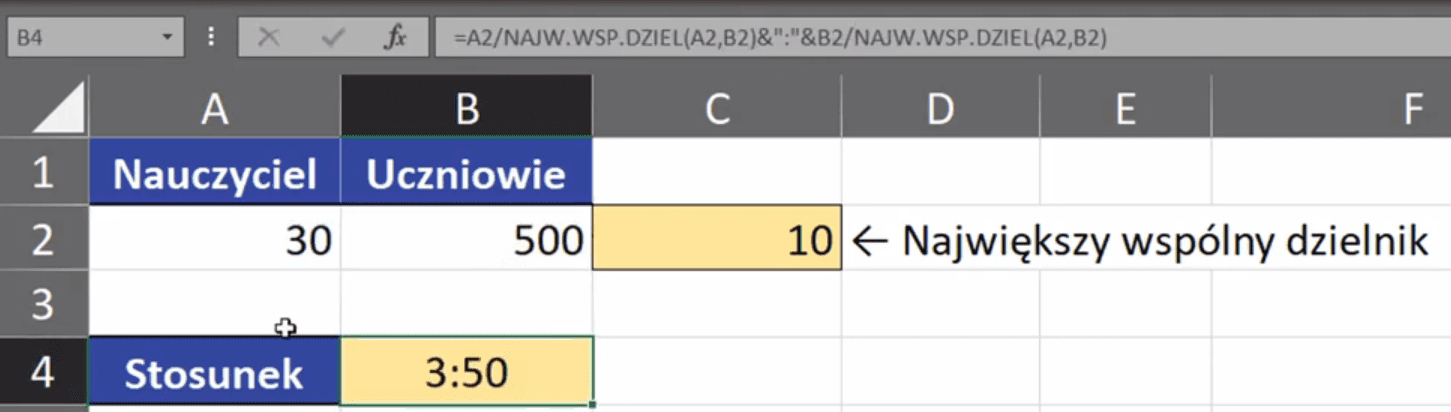
Takie zapisywanie stosunku dwóch liczb jest mało użyteczne. Musimy użyć tutaj formuły, że automatycznie skracała nam taki stosunek do jak najprostszej formy. Potrzebujemy znaleźć wspólny dzielnik obu tych liczb. Excel ma funkcję, która znajduje największy wspólny dzielnik, a nazywa się NAJW.WSP.DZIEL. Kolejne argumenty funkcji to liczba1, liczba2 …, czyli liczby, dla których chcemy znaleźć wspólny dzielnik. Zapis funkcji powinien wyglądać następująco:
=NAJW.WSP.DZIEL(A2;B2)
Otrzymamy wynik funkcji, który przedstawia największy wspólny dzielnik podanych liczb (rys. nr 4).
Rys. nr 4- największy wspólny dzielnik podanych liczb
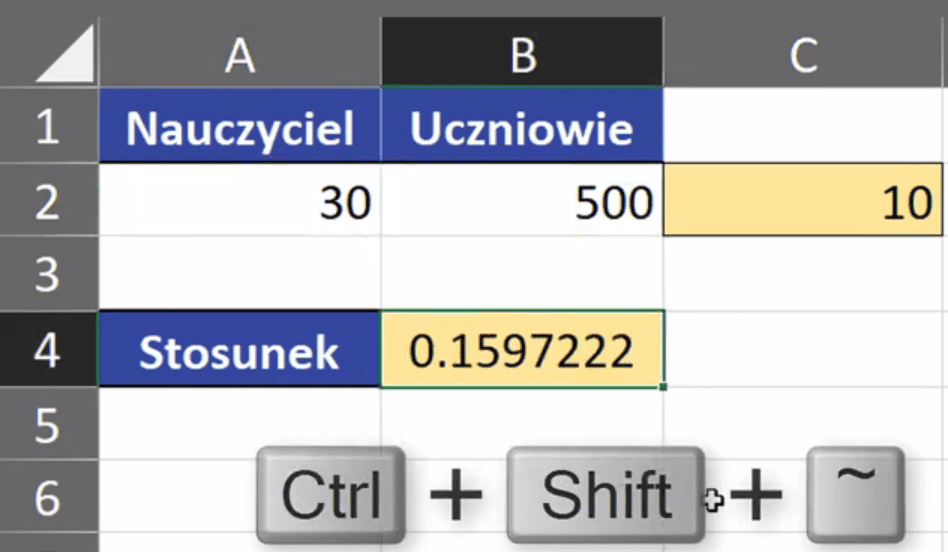
Teraz, kiedy mamy wspólny dzielnik, to chcemy obie liczby podzielić przez niego. Aby podejrzeć rzeczywistą liczbę, jaka powstaje ze stosunku 3:50 musimy użyć skrótu klawiszowego Ctrl+Shift+~ (rys. nr 5).
Rys. nr 5 – stosunek 3:50 przedstawiony jako liczba rzeczywista
Zapis pierwszej części formuły powinien wyglądać następująco:
=A2/NAJW.WSP.DZIEL(A2;B2)
Z tej formuły otrzymamy wynik 3, który następnie chcemy połączyć za pomocą znaków & ze znakiem : i z drugą częścią formuły. Zapis powinien wyglądać następująco:
Powyższą formułę zatwierdzamy. Otrzymamy stosunek dwóch liczb przedstawiony na rys. nr 6.
Rys. nr 6 — stosunek dwóch liczb uzyskany za pomocą formuły
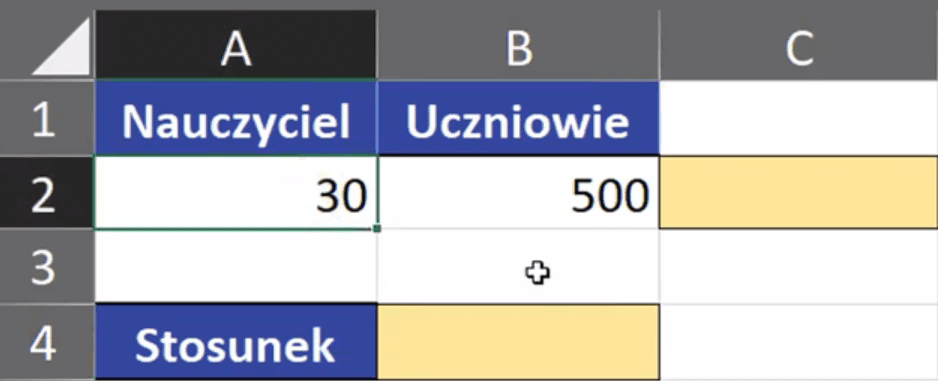
Wynik naszej formuły jest tekstem, a nie liczbą. Nasza formuła jest dynamiczna, czyli po zmianie danych wejściowych, np. 25 nauczycieli otrzymamy poprawiony wynik 1:20, bo największy wspólny dzielnik będzie wynosił 25 (rys. nr 7).
Rys. nr 7 – dynamiczna formuła, wynik po zmianie ilości nauczycieli
Jeśli podamy dwie liczby, które nie mają wspólnego dzielnika, to otrzymamy wynik przedstawiony na rys. nr 8.
Rys. nr 8 – wynik dla liczb bez wspólnego dzielnika
Podsumowując, prosta formuła wykorzystująca funkcje Excela NAJW.WSP.DZIEL może pomóc nam uzyskać uproszczony stosunek dwóch dowolnych liczb.
Ten post jest trochę wyjątkowy, bo dotyczy Świąt Bożego Narodzenia. Do świąt jeszcze daleko, ale jeśli będziecie potrzebować stworzyć coś fajnego dla kolegów i koleżanek w Excelu, to ta porada może wam się przydać.
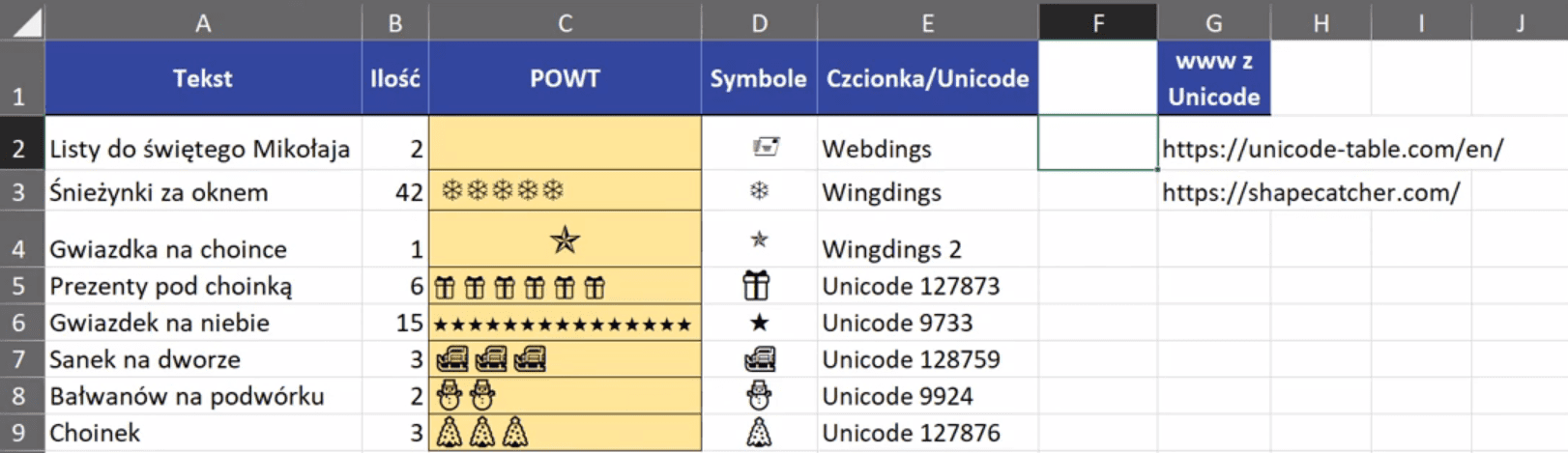
Nauczymy się jak wstawić do Excela dużo gwiazdek, prezentów, choinek, sań Świętego Mikołaja i temu podobnych symboli (rys. nr 1).
Rys. nr 1 – źródła symboli w Excelu
Przede wszystkim musimy znaleźć symbol, którego chcemy użyć. Jedna możliwość to znaleźć czcionkę, która zawiera dużo takich symboli, jak Wingdings, Webdings. Rozwijamy polecenie Symbole (punkt 2 na rys. nr 2) z karty Wstawianie (punkt 1), następnie wybieramy polecenie Symbol (punkt 3).
Rys. nr 2 – polecenie Symbole
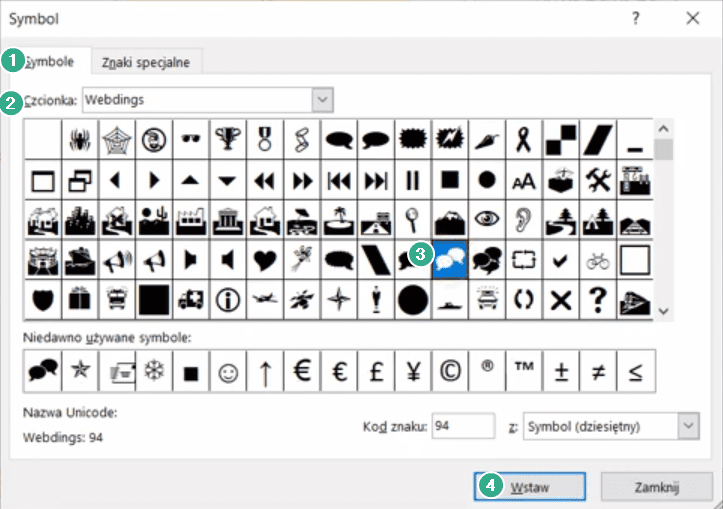
Otworzy nam się okno Symbol, w zakładce Symbole (punkt 1 na rys. nr 3), w polu Czcionka (punkt 2) wybieramy np. Webdings. W kolejnym kroku wybieramy interesujący nas symbol (punkt 3) i klikamy na niego dwukrotnie lub zatwierdzamy przyciskiem Wstaw (punkt 4).
Rys. nr 3 – okno Symbol
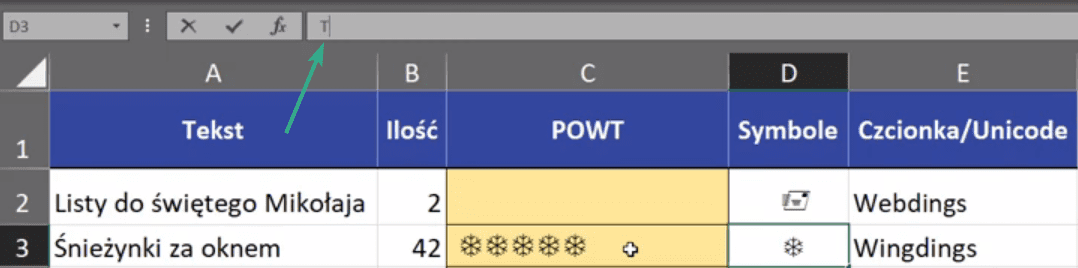
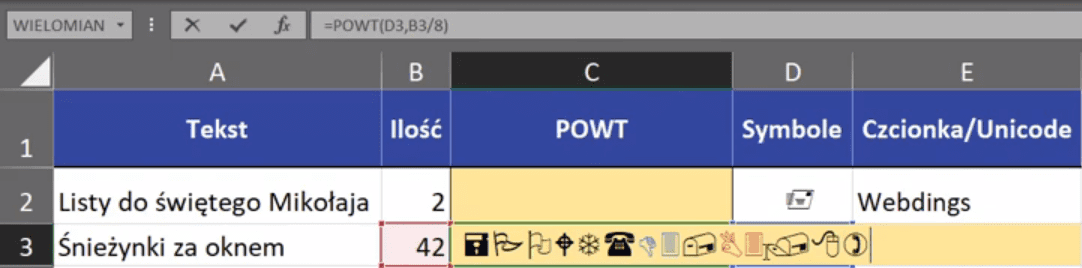
Symbol zostanie wstawiony do komórki, która była aktywna w momencie wybierania polecenia Symbol. Pamiętajmy, że to jest symbol konkretnej czcionki, chociaż my widzimy jakiś znaczek, to "pod spodem" ukryta jest litera. Jeśli zmienimy w tej komórce czcionkę to symbol zniknie a pojawi się litera, która mu odpowiada. Czyli, aby wstawił nam się odpowiedni symbol, to wybrane komórki muszą być sformatowane w danej czcionce na karcie Narzędzia główne. Przykładowo w komórce D3 widzimy gwiazdkę, a na pasku formuły literkę T (zaznaczone strzałką na rys. nr 4).
Rys. nr 4 – symbol i odpowiadająca mu litera
Co ciekawe, w komórce C3 mamy przygotowaną formułę, która wstawia odpowiednią ilość gwiazdek. Jak widać na rys. nr 5 formuła składa się z samych symboli, bo żeby wynik pokazywał się w formie symboli, to komórka musi być sformatowana w tej czcionce. Na szczęście w pasku formuły widać, jaka funkcja została użyta. Użyliśmy funkcji POWT, czyli powtórz, która jeden znak lub cały ciąg znaków powtarza określoną liczbę razy. Zapis formuły powinien wyglądać następująco:
=POWT(D3;B3/8)
Rys. nr 5 – formuła funkcji POWT do wstawienia wybranej ilości takich samych znaków
Ciekawostką funkcji POWT jest, że bierze tylko część całkowitą liczby. Ilość powtórzeń podaliśmy jako działanie 42/8, której wynikiem jest liczba niecałkowita.
Od 5tego wiersza wchodzimy już w znaki Unicode, gdzie mamy bardzo dużo możliwości. Poniżej podajemy dwie strony ze znakami Unicode